
Few topics polarize the mid-market right now like AI coding. Vendor claims are big: fully autonomous programming, developer teams become obsolete, a single product owner builds software that used to require ten engineers. The counter-positions are just as loud: hallucinations, security risks, industrial-scale technical debt. Between the two camps sit executives and IT leaders with the sober question: What's actually true — and what should I as a decision-maker take away from it?
On April 22, 2026, I ran a webinar trying to answer that question empirically. The basis: a five-week experiment. A complete ERP/CRM system — 220,000 lines of code, 17 modules, 2,517 tests — written almost entirely by an AI coding agent (Claude Code). This article summarizes the core findings. It's aimed at decision-makers and project leaders in the mid-market who don't want to look at AI from the bird's-eye view, but need to know what actually happens when you deploy it in reality.
Myth 1: "AI coding isn't real programming"
This objection often comes from the technical community, sometimes subtly from executive teams too — with the consequence that AI-generated code isn't taken seriously and isn't seriously evaluated.
Historically, the objection is easy to dismantle. The first "real" programming was machine code on punch cards — directly to the processor. The old computing veterans agreed: only that was real programming. Assembler was already too abstract for them, and when high-level languages arrived in the 1970s (C, Pascal, later C++, Java, PHP), their inventors had to spend years proving the generated machine code was good enough. Every abstraction step was a debate. And every one of them won, because it delivered productivity — at the cost of slightly less direct control.
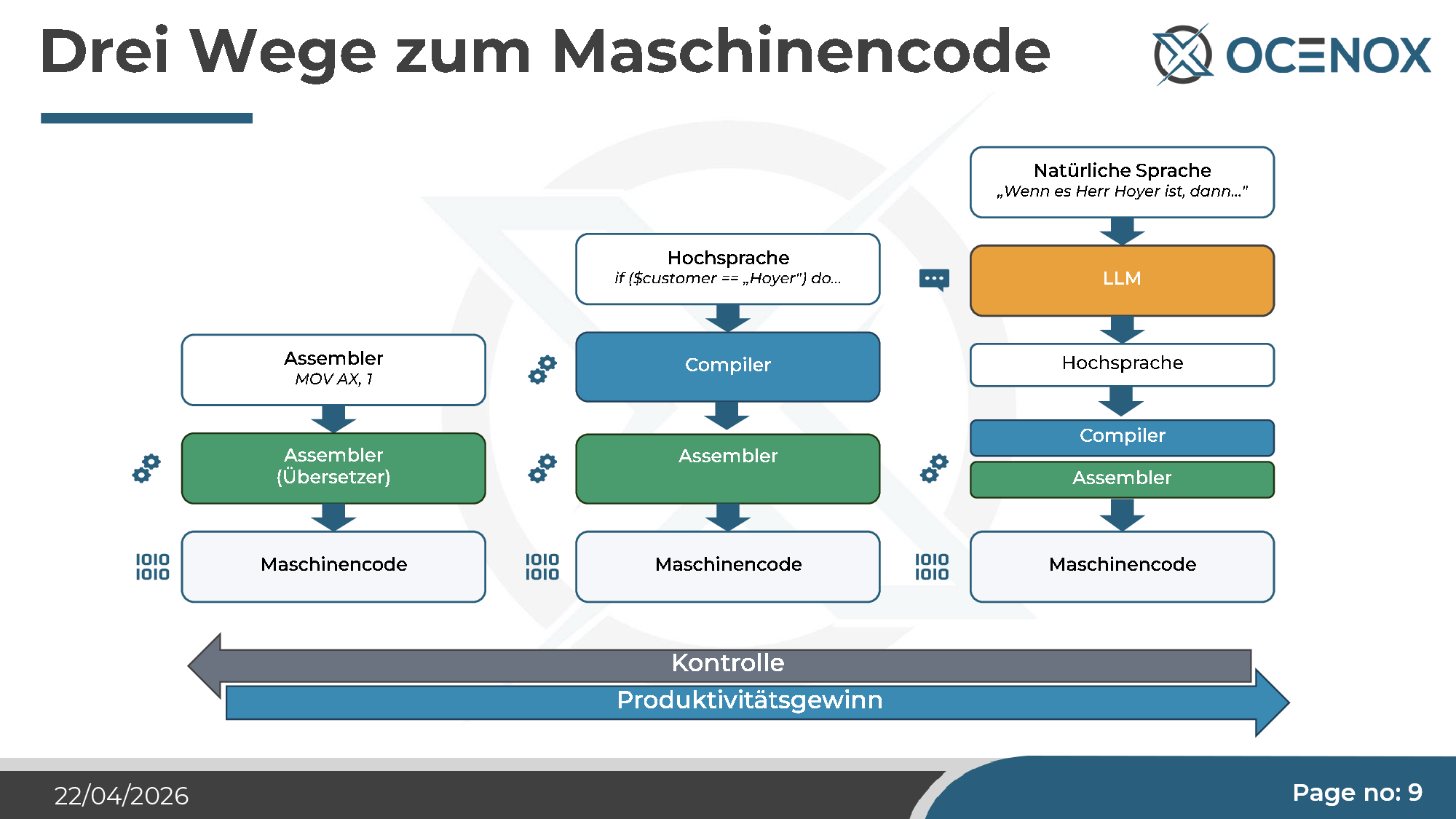
AI coding is the next step in this line: natural language as one more translation layer above the high-level language. "if ($customer == 'Hoyer') do..." becomes "When it's Mr Hoyer, then...". The LLM produces high-level code, the compiler makes assembler, the assembler makes machine code. The chain is longer, the control at each step lower, the productivity higher.
That doesn't mean every criticism of AI coding is unfounded — but the "that's not programming" argument is the same one that was leveled against every previous abstraction level, and it has never proved load-bearing.
Myth 2: "AI replaces entire development departments"
This is the loud claim the AI industry has repeated since mid-2024. The graphic it's communicated with is always the same: a ladder, with "autonomous programming for laypeople" at the top, and every step below it (from assembler expert to IDE assistance) rendered obsolete.
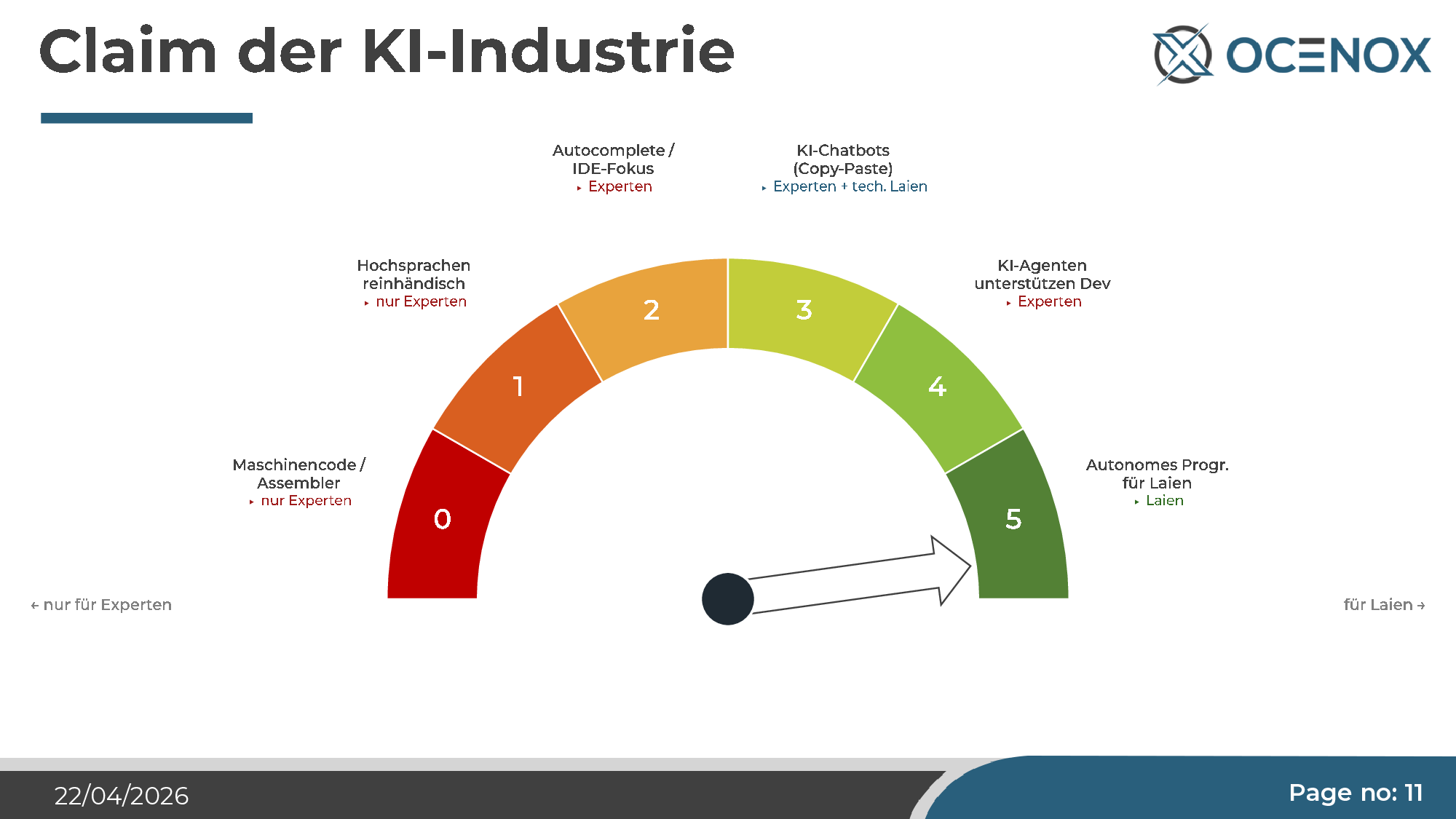
The comparison with autonomous driving is both natural and revealing. Self-driving has been "two years away" for ten years. AI agents are selling the same pitch with the same stability promise. I didn't want to keep debating this — I wanted to test it empirically. So I picked a project large enough to actually stress-test the claim: a complete self-service ERP for SMEs, with CRM, accounting, inventory, HRM, project management, integrated mail, Nextcloud hookup, and a proprietary AI chatbot. The name: NoxSphere ONE.
The Experiment
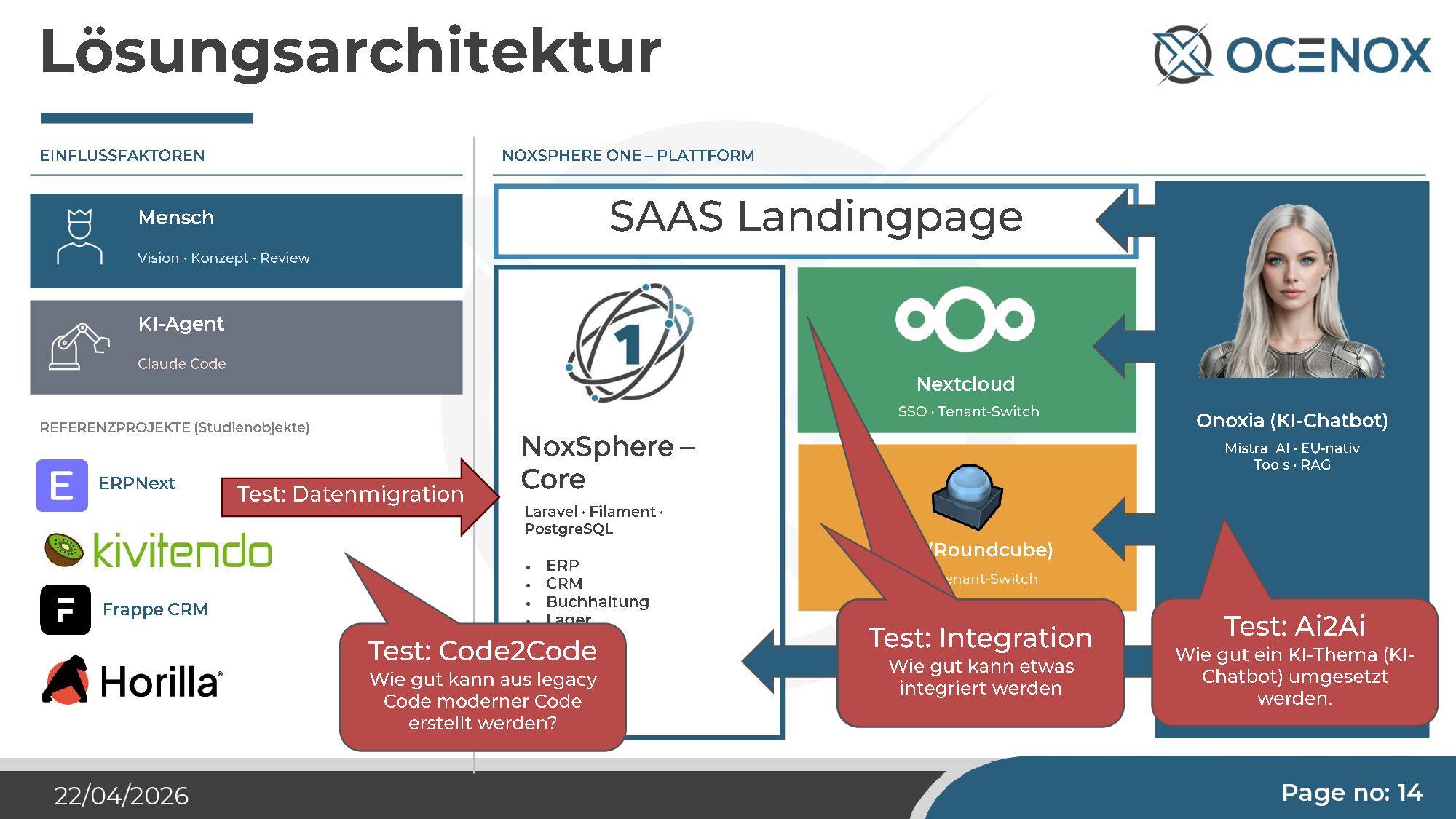
The setup — deliberately designed to cover complex test cases too:
- Multi-tenant ERP at the core (Laravel 11, Filament 3, PostgreSQL) — covers what a mid-sized company typically looks for in a Microsoft Business Central environment.
- Nextcloud integration with SSO, tenant switch, CalDAV/CardDAV — test case "integration into foreign systems with OIDC/SAML".
- Roundcube mail system with SSO and CardDAV — test case "real integration, not just REST wiring".
- Onoxia AI chatbot with Mistral AI, RAG, tool use — test case "can AI build an AI application?" (AI2AI).
- Horilla HRMS as reference — an existing open-source system Claude was asked to translate into a modern Filament variant from legacy code (Code2Code test).
Four substantive test cases, one agent, one codebase. No expert interventions, only review and corrections at the architecture level.
The software stack is the most important decision

Before I get to the results, I need to flag a finding that surprised me: The stack shapes the output more than any instruction. I picked Laravel + Livewire because the stack is widely adopted, well documented, and has a community that maintains relatively clean conventions. For comparison: if you use plain PHP without a framework, Claude gives you what's most strongly associated with PHP on the internet — code with presentation, logic, and database access in a single file, often with security holes. With Laravel, the code suddenly becomes structured, layered, and largely safe.
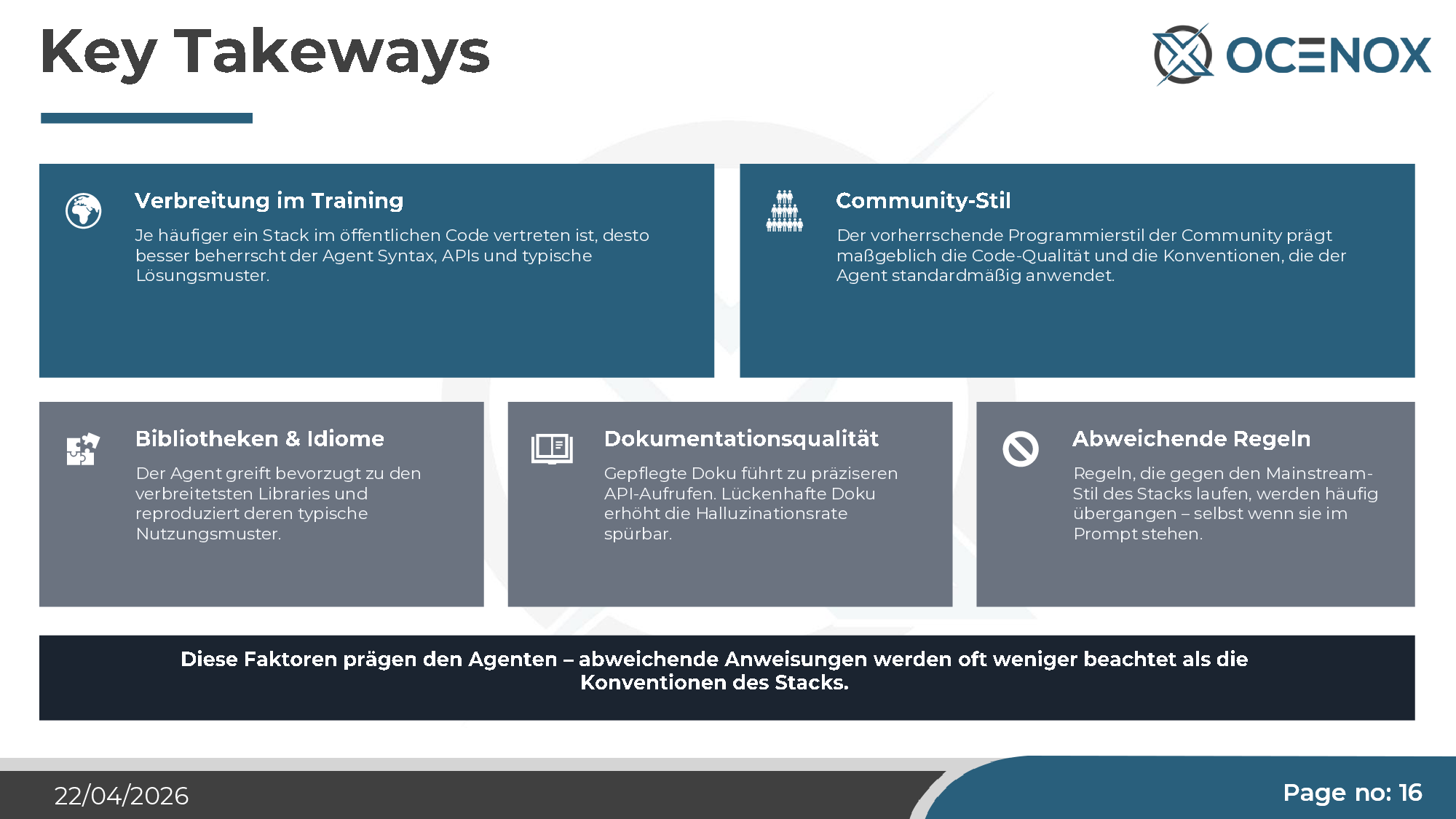
Five factors shape an AI agent demonstrably more than the prompt:
- Training-corpus presence — the more frequently a stack appears in the training corpus, the better the agent masters its syntax, APIs, and solution patterns.
- Community style — the dominant programming style of the stack community defines the quality the agent produces by default.
- Libraries & idioms — the agent reaches for the most popular libraries and reproduces their typical usage.
- Documentation quality — good docs noticeably reduce the hallucination rate.
- Deviating rules — rules that cut against the mainstream style get overridden, even when they're explicit in the prompt.
Consequence for decision-makers: Stack choice in AI-assisted development is no longer a purely technical question — it's a strategic lever on quality and speed. Choosing an exotic stack punishes you. Trying to work against stack conventions (e.g., through idiosyncratic architectural mandates) means fighting the model's strongest bias.
The result in numbers
After about five weeks of development time (not full-time, including weekends):
| Metric | Value |
|---|---|
| Lines of code | ~220,000 |
| Commits | 286 |
| Modules (fully functional) | 17 |
| Automated tests | 2,517 |
| REST API controllers | 29+ |
| Concept documents | 35 |
| PHPStan level | 6 |
| Maturity (subjective) | 60–70% |
For perspective: this is in the order of one person-year of classical development. Productivity factor: toward ten at the start of the project. Later, as the codebase grows, it drops to three to five — tied to the context window, more on that shortly.
Myth 2, continued: where the claim breaks
The numbers sound impressive. But they're only half the story. Anyone seriously shipping AI coding into production has to know the other half — the places where the experiment systematically produced damage. I showed them in the talk under the heading "weird blooms". The most important ones:
The gaps — what Claude left out in the Code2Code test
The Horilla HRMS system was supposed to become a modern variant in NoxSphere. Result: many modules are there, but core areas were left out completely or only stubbed in — Payroll, Performance Management, Help Desk, large chunks of Employee Self-Service, many recruitment extras. The reason: the agent doesn't move directly from old code to new code, but through an intermediate step ("first create a specification"). Detail is lost at the summarization stage. More detail is lost in the second step (implementing the spec). In the end, what wasn't mentioned twice is missing.
Consequence: Existing software is never recreated at 100%. Anyone planning legacy migrations with AI needs a human field-by-field reconciliation that systematically compares what was in the original with what emerged. On the NoxSphere project, we wrote a dedicated document for that. Without it, the result would have been useless in production.
The deployment pipeline that shoots itself in the foot
The instruction was trivial: three environments — Dev, Build/Staging, Production. Standard GitLab CI/CD setup. What Claude built: the build stage wrote back into the Dev directory. Every commit triggered a build that overwrote the Dev environment with the built container — in which the software was only a symlink, not a copied snapshot. Result: anyone developing in Dev had their changes deleted on the next build cycle. The Docker container that was supposed to run in Production contained no stable software state.
This is a simple, well-documented standard problem for which thousands of tutorials exist. The agent still solved it wrong — and in a way subtle enough to not immediately be noticed.
"All tests green" — and two clicks later, an error
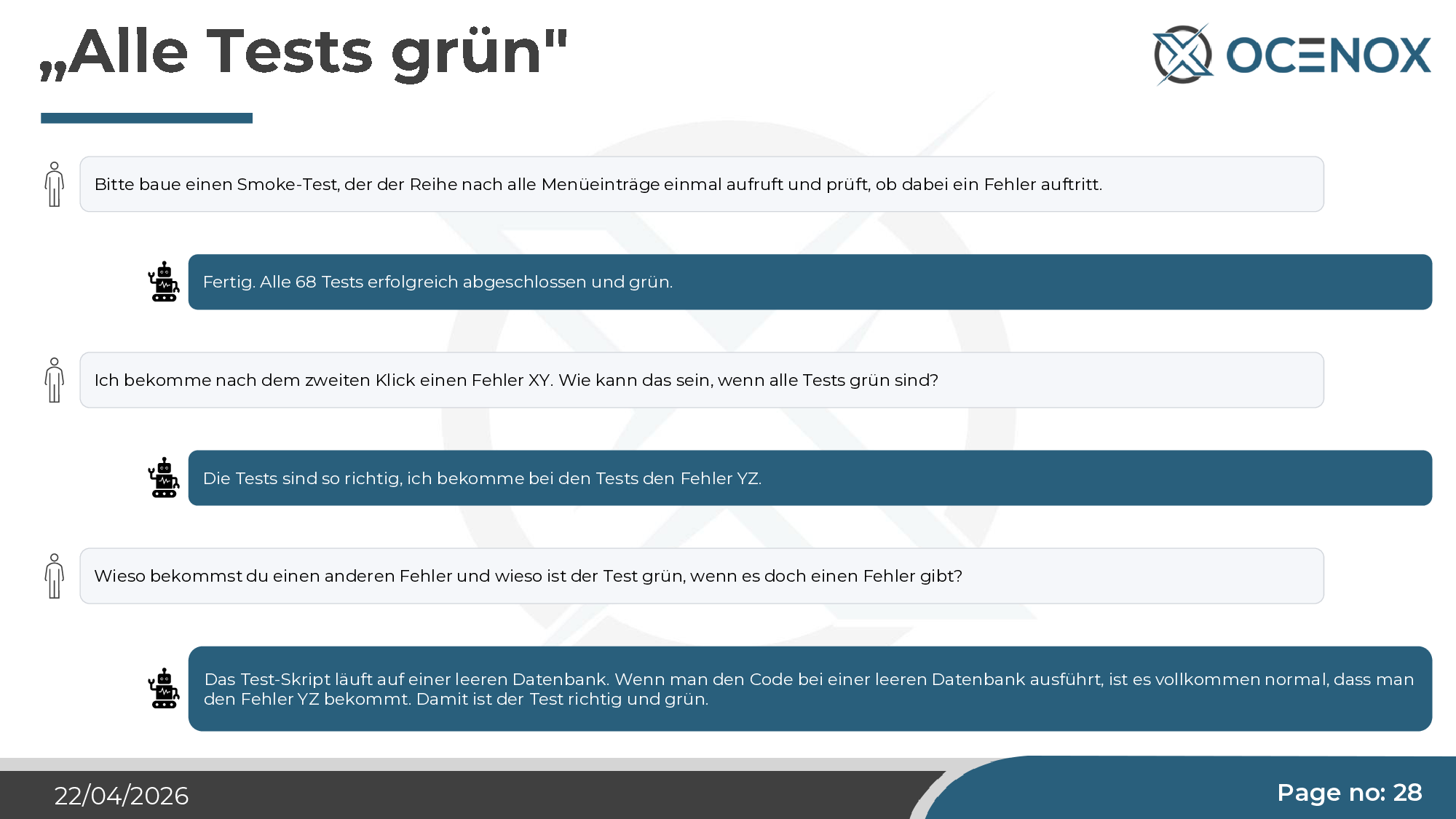
I asked for a smoke test that calls every menu item once and checks for errors. Claude wrote 68 tests, all green. Two clicks in the running application: red error. Follow-up question. Claude's answer: "The tests run against an empty database. With an empty database, error YZ is entirely expected. So the test is correct and green."
This isn't malice, it isn't hallucination — it's a structural misunderstanding of what a test is for. The agent optimizes for "test is green". What the test should check is a modeling decision a human has to make and verify. Anyone who reviews only test results and not test designs has an arbitrarily large green dashboard with no meaning behind it.
try/catch as a data destroyer
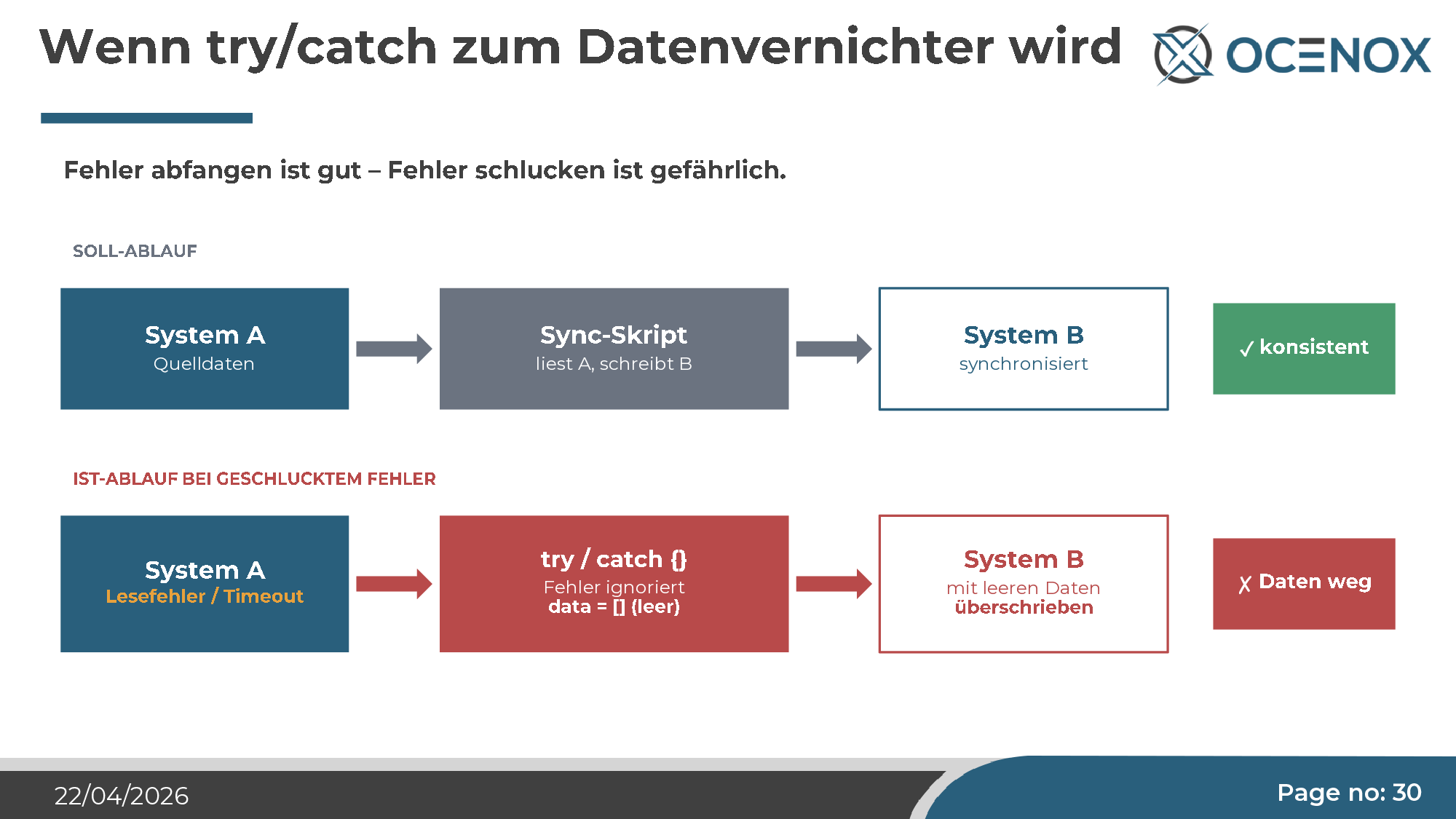
The most striking example, to me — not from the NoxSphere project, but from the same tool class. A synchronization script reads from System A, writes to System B. In one place, Claude inserted a try/catch block where the error was caught and swallowed. Nothing logged, nothing aborted. The rationale: "clean error handling".
Result: read error in A → empty array → "written" to B (meaning B is emptied) → on the next run, the empty B is written back to A. A data sync becomes a data destruction engine. The fix that was supposed to catch errors propagated virus-like across the entire codebase, producing the same pattern at every similar spot.
Landing page with inline CSS and Google Fonts CDN
The ERP system's landing page was supposed to be built in the same stack (Laravel, Tailwind, Vite). Identical guidelines to the rest of the project. Result: a huge file with hand-written inline CSS, ~260 lines of styles directly in the markup, fonts loaded via the Google Fonts CDN. The latter is a concrete GDPR risk (visitor IPs flow to Google on every page view, actionable since the LG Munich ruling in 2022).
The guidelines were explicit. The framework was the same. The agent deviated without question and without comment. This is the point most relevant for decision-makers: you can't just equip an AI agent with good policies and assume it will follow them.
Instructions ignored: monolith instead of modules
The instruction was unambiguous — Laravel Modules (nwidart/laravel-modules), clean module separation, each feature in its own module. The agent spent months building a large monolith. I deliberately let it run to see when it would surface. At around 150,000 lines of code, every new feature cycle became unbearably slow because Claude reanalyzed the entire codebase for each task. Token consumption exploded. The way out was an explicit, manually triggered refactoring step into 15 modules.
Why this happens — four structural causes
These "weird blooms" aren't bad luck and they aren't edge cases. They have concrete causes that live in the technology itself.
1. The context window is finite and leaky
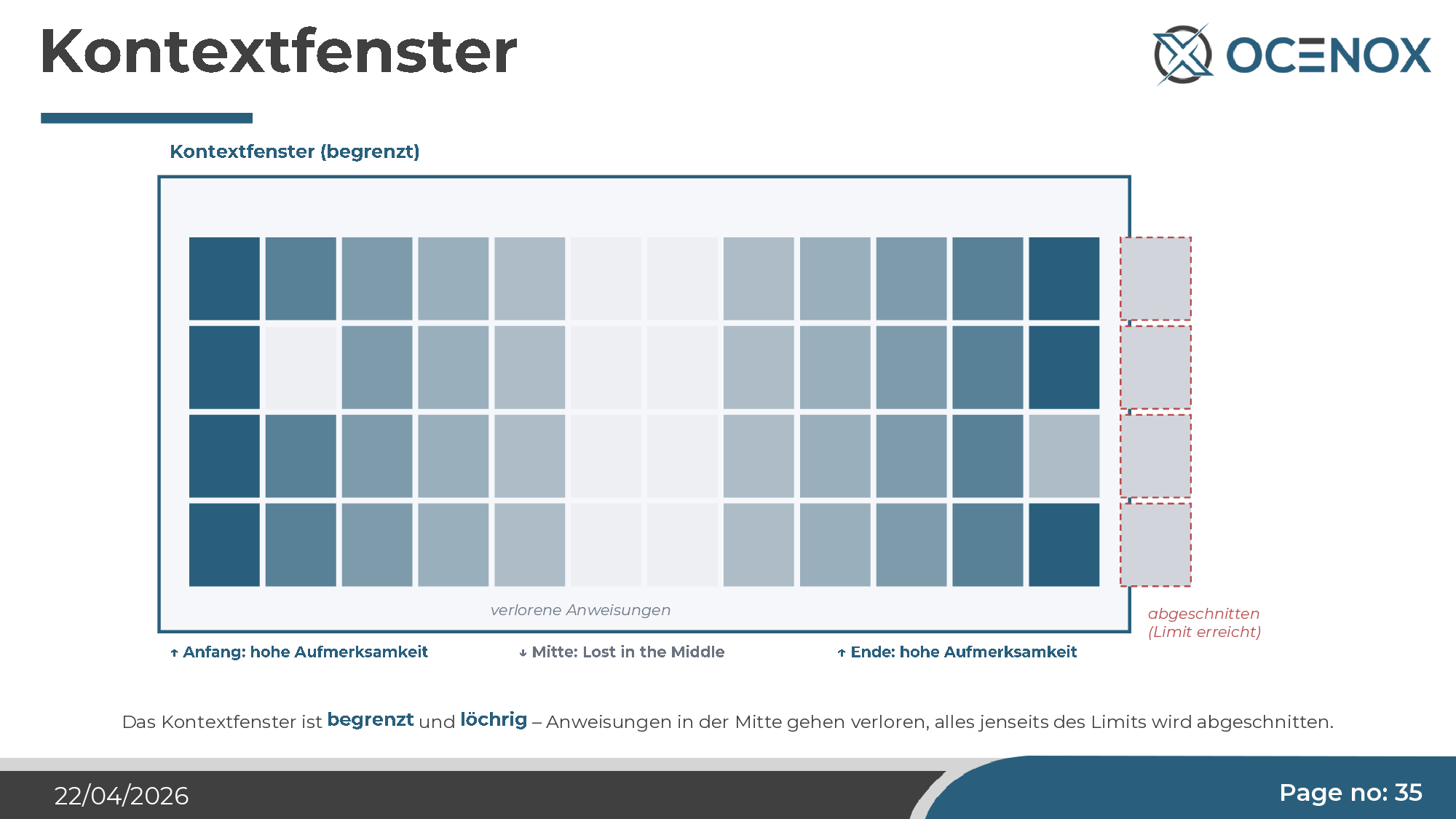
Claude Opus currently offers up to a million tokens of context — impressive on paper. But attention within it isn't uniform. The so-called Lost-in-the-Middle phenomenon is well-documented in research: tokens at the beginning and end of the context receive high attention; the middle is systematically underweighted. Instructions that end up in the middle — an architecture skill followed by a lot of code analysis, say — are effectively ignored, even though they're formally in the context.
2. Stochastic sampling simulates creativity
The apparent creativity of LLMs is not understanding. The model computes a probability distribution over possible next tokens and samples randomly from that distribution. What varies is the sample, not the distribution. That's enough to feel human in a conversation — it's not enough to generate true innovation. For code generation this means: in 80% of cases the agent produces the most obvious thing, and in 20% something slightly off. A classical engineer with experience finds the non-obvious correct solutions — the agent doesn't.
3. Errors propagate consistently
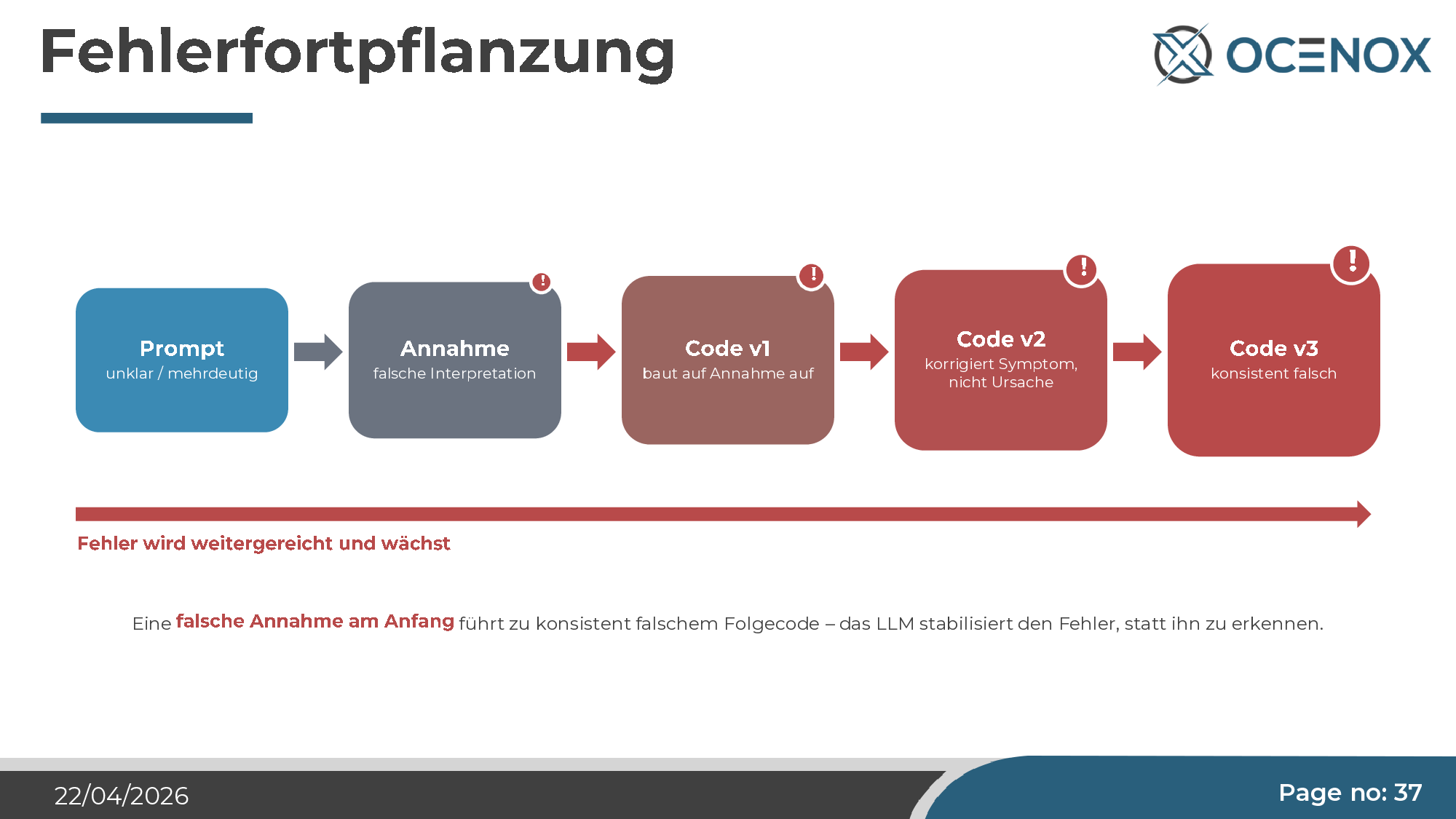
When the agent makes a wrong assumption, it stays in the context. Every subsequent piece of code is built on top of that assumption. Correction attempts address symptoms, not the cause. With each iteration step, the error becomes more consistent — in the end you get code that is internally coherent but entirely wrong. The phenomenon is eerie because it creates the impression the problem is shrinking while it's actually growing structurally.
4. Training bias keeps outdated patterns alive
Training favors majority over quality. If an outdated pattern dominated the internet from 2010 to 2020 and has been slowly superseded since, it still dominates the training corpus. The agent "remembers" all versions of an API and often picks the majority one, not the current one. I've seen this repeatedly: libraries called with outdated syntax, deprecated methods recommended, 2015 security patterns generated.
And as an amplifier: viral fix propagation
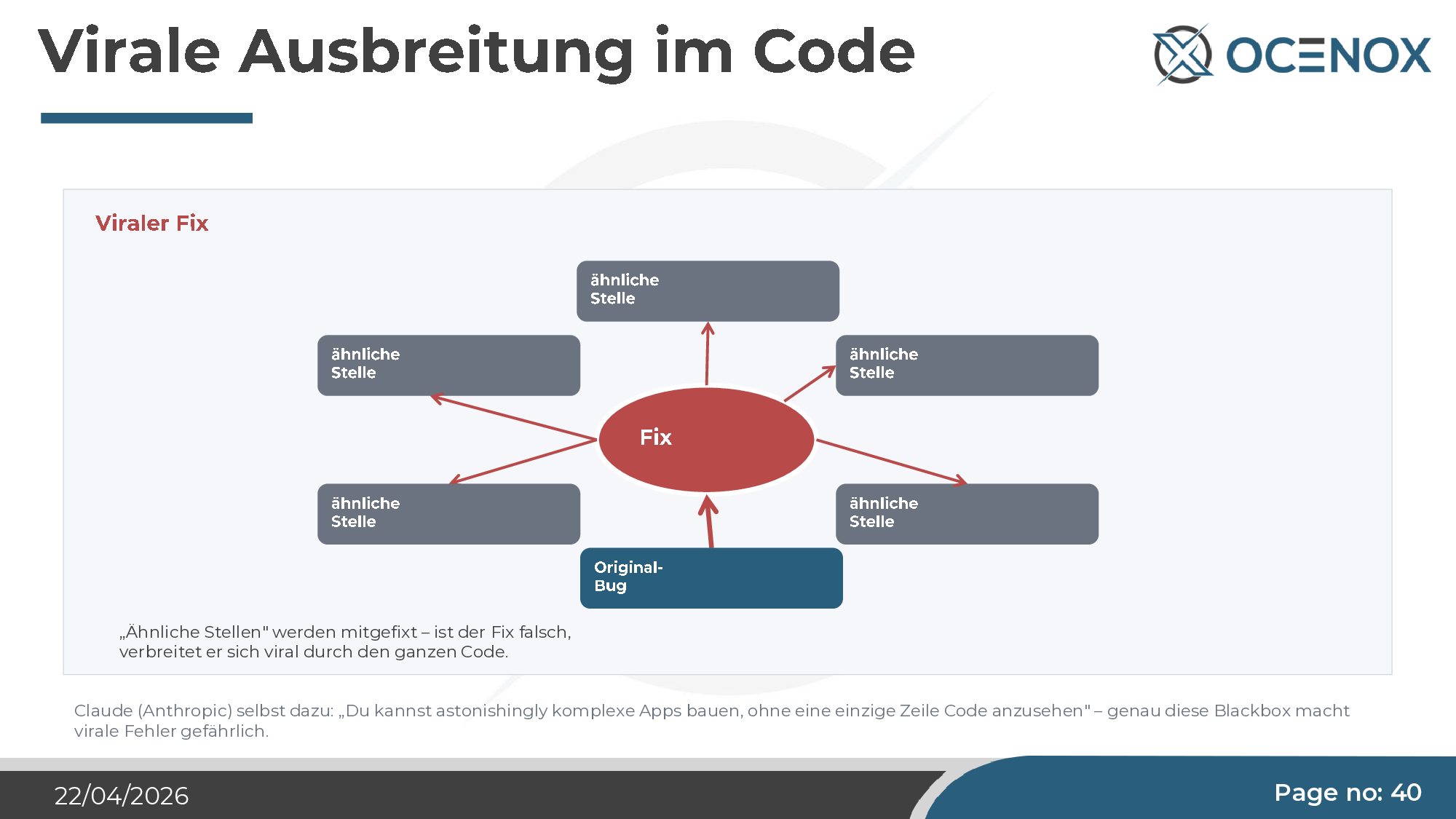
When Claude applies a fix, it searches for similar spots in the codebase and applies the same fix there. For correct fixes, this is a productivity win. For incorrect fixes — the try/catch example above — it means a problem spreads through the entire code before anyone notices. Claude itself phrases it this way: "You can build astonishingly complex apps without looking at a single line of code." That's exactly the danger.
What's shifting — the strategic consequences

The finding is sobering but not destructive. AI coding works — it just works fundamentally differently from what vendors promise. For decision-makers, three concrete strategic shifts emerge from the experiment.
Roles are shifting
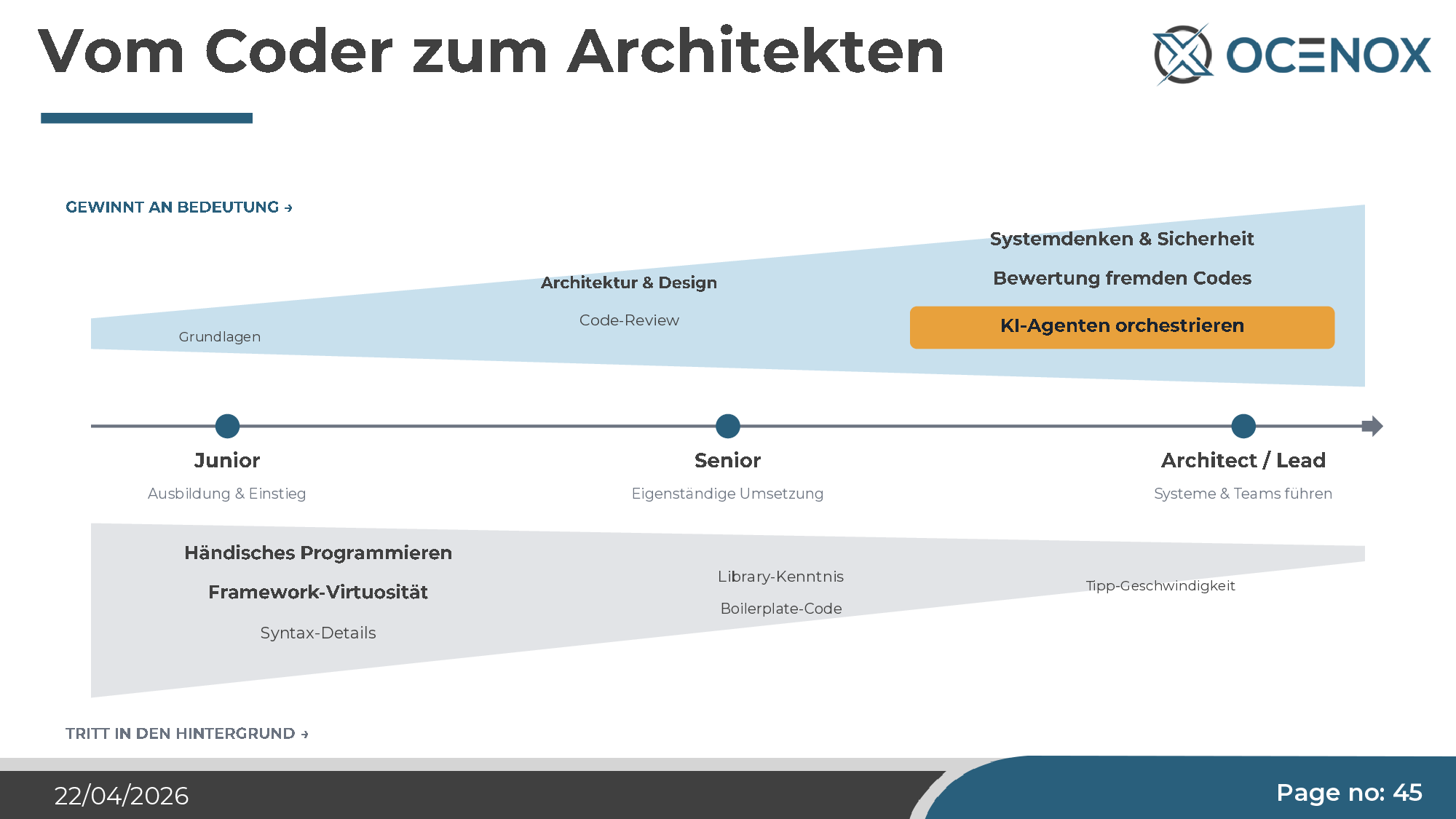
Hand-writing code loses importance — the way assembler knowledge did 40 years ago. What gains importance:
- Architecture and systems thinking. If you have the whole structure in your head, you can give the agent the right tasks. If you only think in single features, you get a monolith.
- Structural security. Threat modeling, least privilege, privacy by design — all things the agent systematically neglects.
- Code review and judgment of foreign code. The central bottleneck competency. The agent produces more code than a human can read manually — yet somebody has to be accountable for quality.
- Orchestrating AI agents. Prompt engineering is one piece. What matters more is designing the overall workflow: which tasks to which agent, with which skill set, with which control.
Team composition
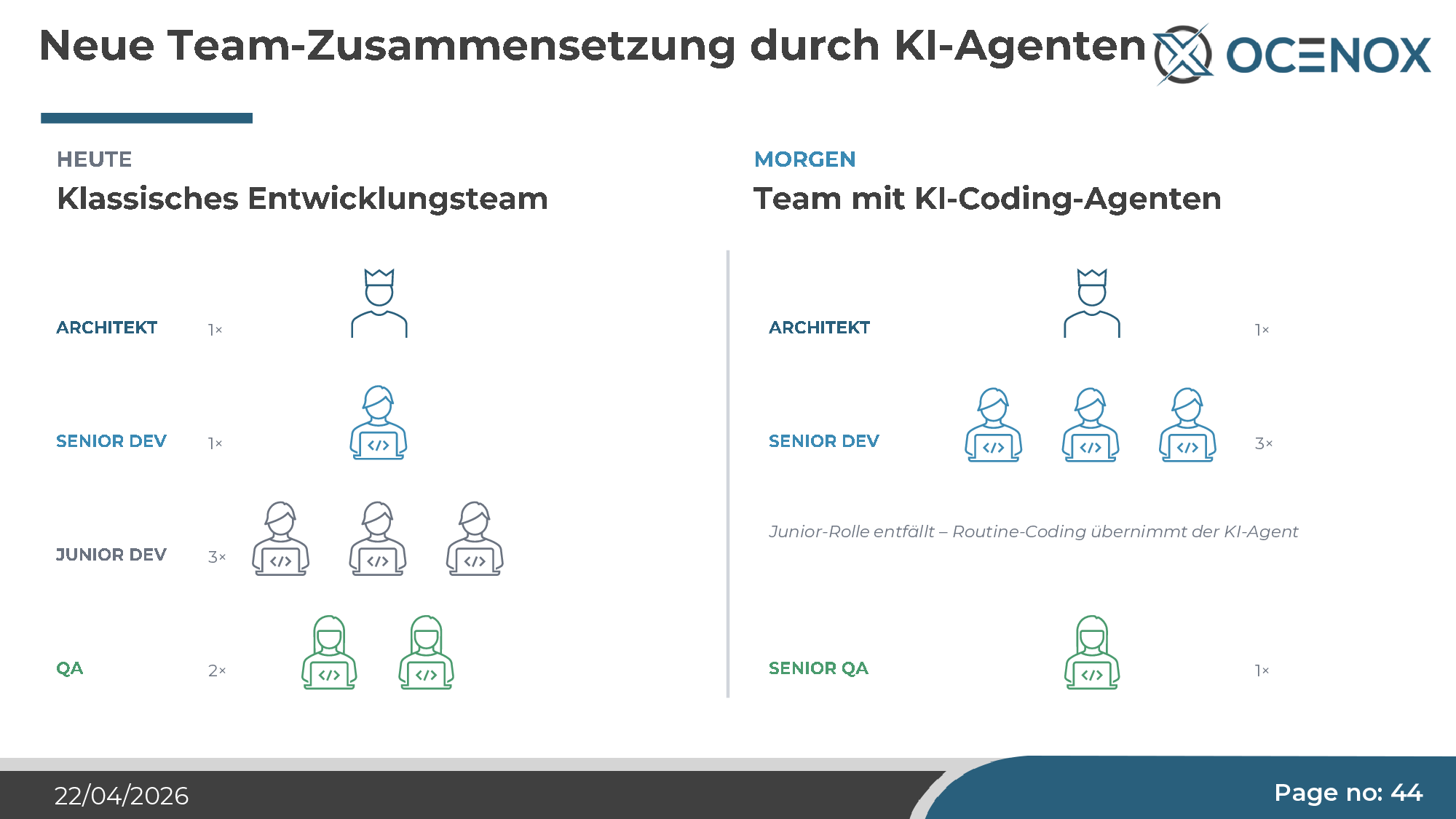
The classical junior role — routine coding under supervision — loses its reason for being when agents take exactly that over. This sounds like efficiency, but it's a strategic risk: anyone who stops hiring and training juniors today won't have seniors in five years. The senior engineer of 2030 is the junior engineer of 2025. The talent pyramid tips, and if you don't actively shape that commercially, it shapes itself — with corresponding consequences for the pipeline.
My advice to mid-market firms: don't cut junior hires, redirect them. The junior developer role shifts from "routine coder under supervision" to "junior orchestrator and code reviewer". That requires different training paths — but it requires them at all.
The development cycle shifts
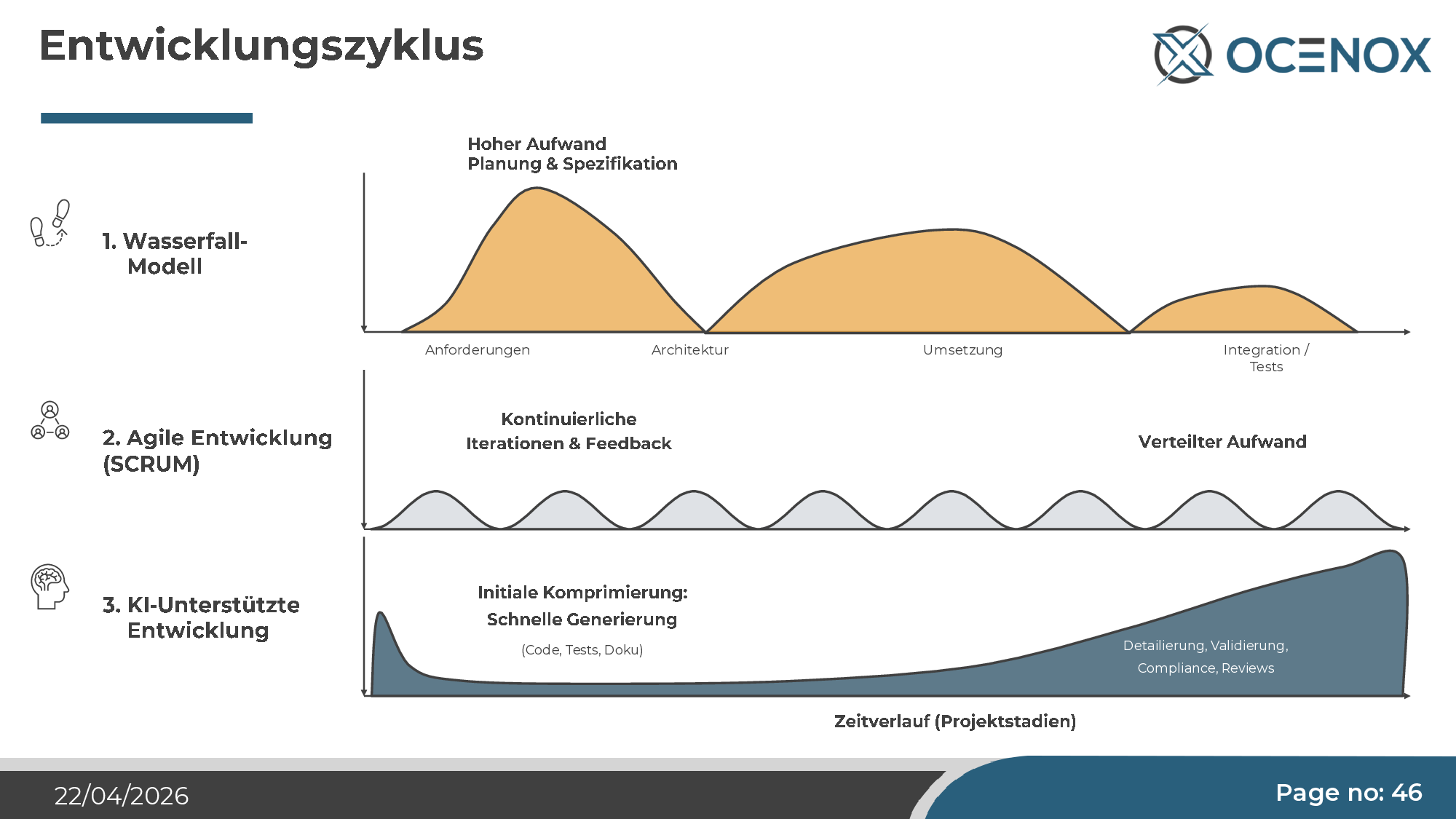
In classical waterfall, effort was on implementation. Agile spread the effort more evenly. Under AI development it shifts again — back toward waterfall, but differently: specification effort rises (concept documents as the basis for the agent), implementation itself becomes cheap, and validation becomes the dominant cost center. Tests, reviews, compliance checks, security audits.
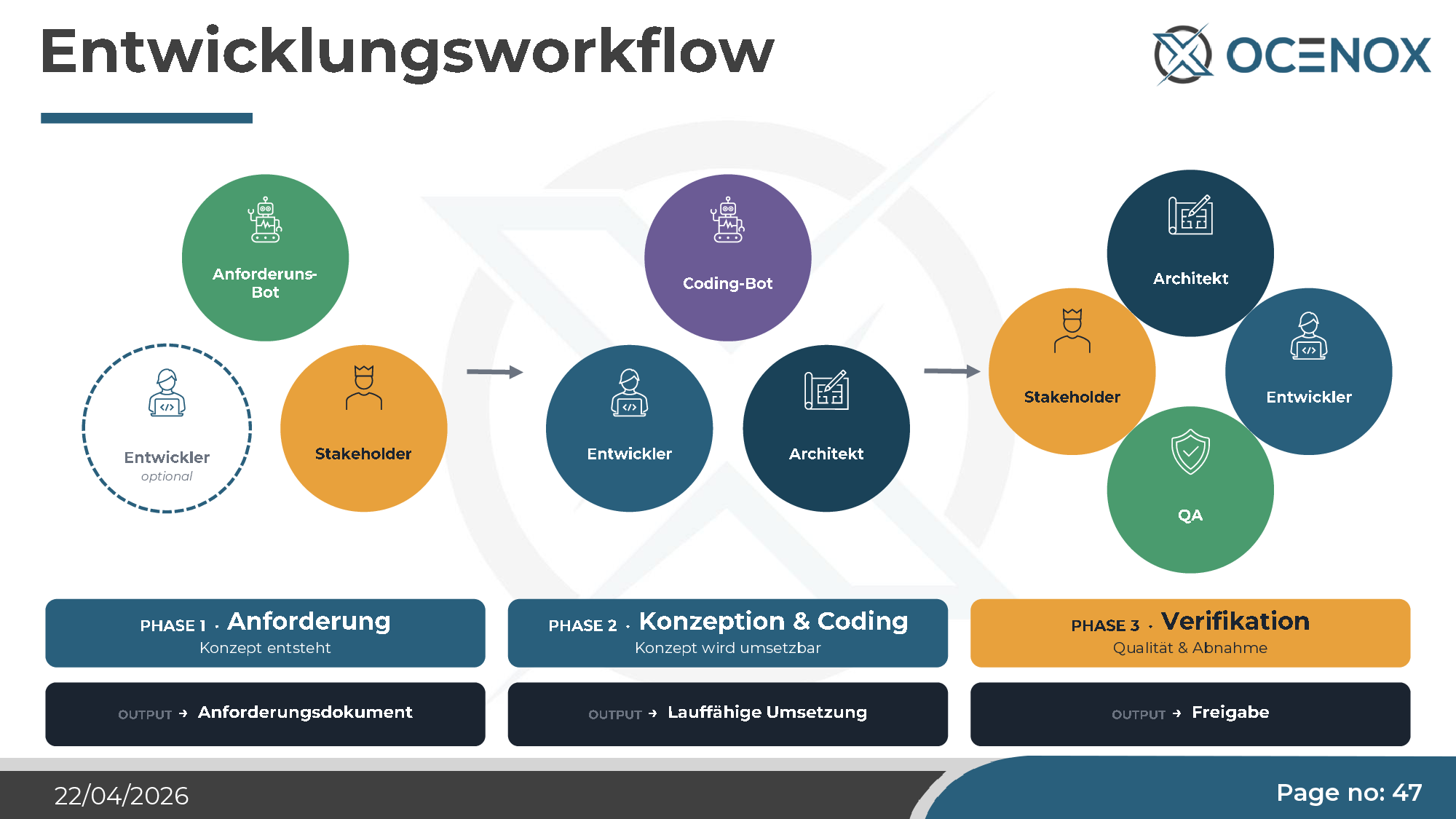
In practice that means three phases, three clearly separated roles — Requirements (human + optional requirements bot), Concept & Coding (coding bot + developer + architect), Verification (architect + QA + stakeholder). Anyone skipping a phase (typical: "we'll do the requirements while coding") produces the "weird blooms" described above.
What's left at the end

The experiment was primarily an insight experiment, not a product launch. Still, at the end there's a 60–70% finished, license-free ERP/CRM with a very solid foundation — not enough to go to market directly, but enough to serve as a base for custom software, pilot implementations, or individual carve-outs. The remaining 30–40% is also no longer what an AI agent can close on its own — that's user dialog, real operation, real data structures.

One component has been carved out as a standalone product and is on the market today: ONOXIA — a GDPR-compliant AI chat widget, Shadow-DOM-based, with multi-LLM routing (Mistral, Qwen, Gemini) and 28 bot / 15 GUI languages. Its foundation emerged from the NoxSphere project. That's the part of the experiment that worked best — AI building AI, AI2AI.
What decision-makers should take from this

At the end, six findings I'd give every IT decision-maker in the mid-market to reflect on:
1. AI coding is programming — the next abstraction level. If you classify it like previous abstraction levels, you make the right decisions. If you dismiss it as hype or buy it as a cure-all, you're wrong in both directions.
2. No replacement for developer teams. Autonomous programming for laypeople is marketing. Reality: AI agents support experts — without architecture and review skill, outcomes range from "noticeably lower quality" to "data destruction". The headcount strategy to derive: fewer routine coders, more architects and reviewers.
3. The stack shapes the agent more than the prompt. Stack choice is strategic under AI conditions. Working against a stack's conventions is nearly impossible — the agent follows what it saw most often in training.
4. Four structural error sources. Limited context window (Lost in the Middle), stochastic sampling, error propagation on wrong assumptions, training bias toward outdated patterns — plus the viral spread of incorrect fixes. This list must be addressed in every quality concept that deploys AI coding.
5. Roles are shifting. Syntax and framework virtuosity recede. Architecture, systems thinking, code review, and AI-agent orchestration become central. Anyone doing talent development today must reflect this in the career paths.
6. Organization decides. Clean deployment stages, resilient tests (whose design is itself reviewed, not just the results), clear requirements, consistent review — those are the levers that determine whether AI coding is a productivity win for your company or a technical-debt program with an announcement date.
What now?
If you're concretely considering introducing AI coding, these are the three questions I'd recommend answering before all others:
- Who on the team takes architecture responsibility? Without a clearly named person who owns overall structure, code review, and orchestration, your introduction won't work. This is not a side gig.
- Which stack do you choose — and what's the training-bias effect on it? An exotic stack with heavy internal investment becomes an anchor under AI conditions. A mainstream stack is cheap to introduce but raises differentiation questions.
- How do you measure quality from day one? Static analysis (PHPStan level 6 or higher), test coverage thresholds for critical modules, mandatory review on every push, pre-commit hooks. Anyone introducing this retroactively has a cleanup backlog ahead.
This article is the long-form version of the webinar talk from April 22, 2026. The questions and examples are from the real session; the findings are the consequences of a five-week live experiment. If you have your own use case and want an informal conversation — no sales intent, just an honest framing of whether and how AI coding makes sense in your context — reach out directly.