
")

Kaum ein Thema polarisiert im Mittelstand aktuell so wie KI-Coding. Die Claims der Anbieter sind groß: Vollautonomes Programmieren, Entwicklerteams werden obsolet, ein einzelner Product Owner baut Software, für die früher zehn Entwickler nötig waren. Die Gegenpositionen sind ebenso laut: Halluzinationen, Sicherheitsrisiken, technische Schulden im industriellen Maßstab. Zwischen beiden Lagern sitzen Geschäftsführer und IT-Leitungen mit der nüchternen Frage: Was stimmt jetzt eigentlich — und was muss ich als Entscheider daraus ziehen?
Am 22. April 2026 habe ich in einem Webinar versucht, diese Frage empirisch zu beantworten. Grundlage war ein über fünf Wochen durchgeführtes Experiment: Ein vollständiges ERP/CRM-System — 220.000 Code-Zeilen, 17 Module, 2.517 Tests — zum allergrößten Teil durch einen KI-Coding-Agenten (Claude Code) geschrieben. Dieser Artikel fasst die Kernbefunde zusammen. Er richtet sich an Entscheider und Projektleiter im Mittelstand, die KI nicht aus der Vogelperspektive betrachten wollen, sondern wissen müssen, was in der Realität passiert, wenn man es wirklich einsetzt.
Mythos 1: „KI-Coding ist kein echtes Programmieren"
Dieser Einwand kommt oft aus der technischen Community, manchmal unterschwellig auch aus Geschäftsleitungen — mit der Konsequenz, dass man KI-generierten Code nicht ernst nimmt und nicht ernsthaft evaluiert.
Historisch ist der Einwand leicht zu entkräften. Das erste „echte" Programmieren war Maschinencode auf Lochkarten — direkt an den Prozessor. Die alten Veteranen der Informatik waren sich einig, dass nur das richtiges Programmieren sei. Schon Assembler war ihnen zu abstrakt, und als in den 70er-Jahren die Hochsprachen kamen (C, Pascal, später C++, Java, PHP), mussten deren Erfinder lange beweisen, dass der generierte Maschinencode gut genug war. Jeder Abstraktionsschritt war eine Diskussion. Und jeder hat sich durchgesetzt, weil er Produktivität gebracht hat — bei etwas weniger direkter Kontrolle.
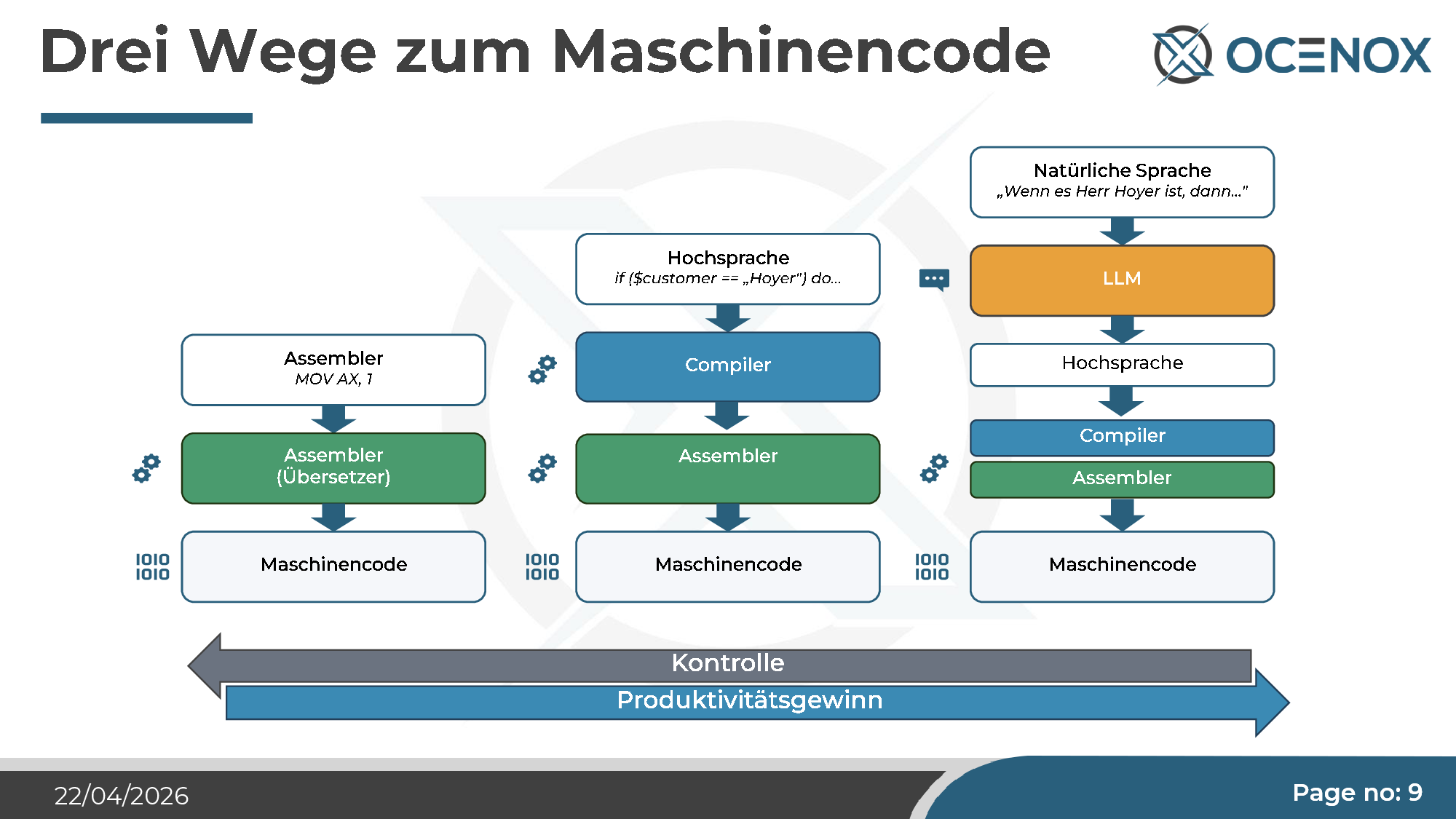
KI-Coding ist in dieser Linie die nächste Stufe: Natürliche Sprache als weiterer Übersetzungsschritt über der Hochsprache. Aus „if ($customer == 'Hoyer') do..." wird „Wenn es Herr Hoyer ist, dann...". Der LLM produziert Hochsprache, der Compiler macht Assembler, der Assembler macht Maschinencode. Die Kette ist länger, die Kontrolle auf jeder Stufe geringer, die Produktivität höher.
Das heißt nicht, dass jeder Kritikpunkt an KI-Coding unbegründet ist — aber die Argumentation „das ist kein Programmieren" ist dieselbe, die zu jeder vorhergehenden Abstraktionsebene vorgebracht wurde, und sie hat sich noch nie als tragend erwiesen.
Mythos 2: „KI ersetzt ganze Entwicklungsabteilungen"
Das ist der laute Claim, den die KI-Industrie seit Mitte 2024 wiederholt. Die Grafik, mit der er kommuniziert wird, ist immer dieselbe: eine Leiter, an deren oberstem Ende „autonomes Programmieren für Laien" steht, und alle darunter liegenden Stufen (vom Assembler-Experten bis zur IDE-Unterstützung) werden obsolet.
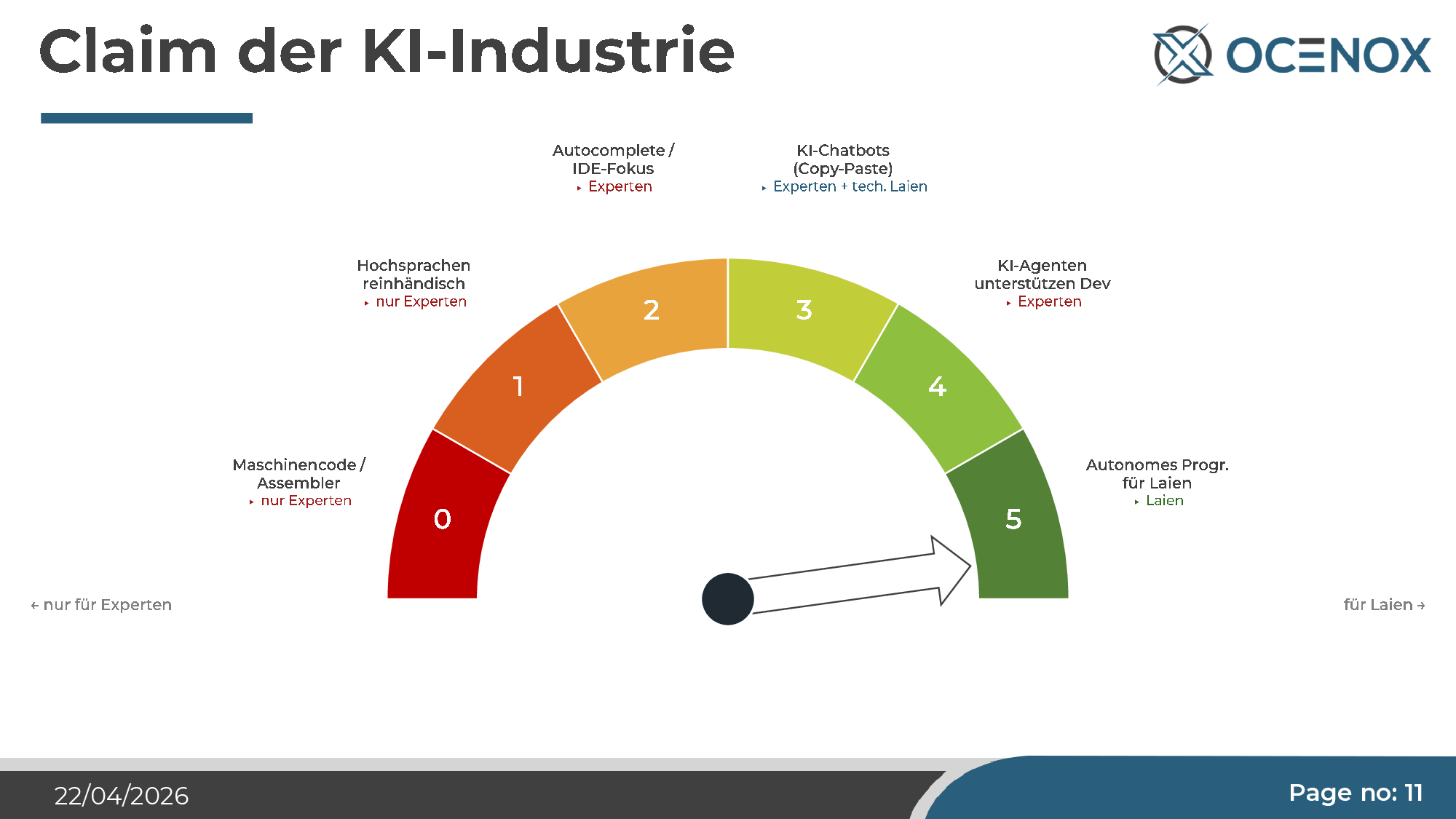
Der Vergleich mit autonomem Fahren ist dabei naheliegend — und entlarvend. Autonomes Fahren ist seit zehn Jahren zwei Jahre entfernt. KI-Agenten verkaufen den gleichen Pitch mit dem gleichen Stabilitätsversprechen. Ich wollte das nicht mehr nur diskutieren, sondern empirisch prüfen. Also habe ich mir ein Projekt gesucht, das groß genug ist, um den Claim tatsächlich zu testen: Ein vollständiges Self-Service-ERP für KMU, mit CRM, Buchhaltung, Lager, HRM, Projektmanagement, integriertem Mailsystem, Nextcloud-Anbindung und einem eigenen KI-Chatbot. Der Name: NoxSphere ONE.
Das Experiment
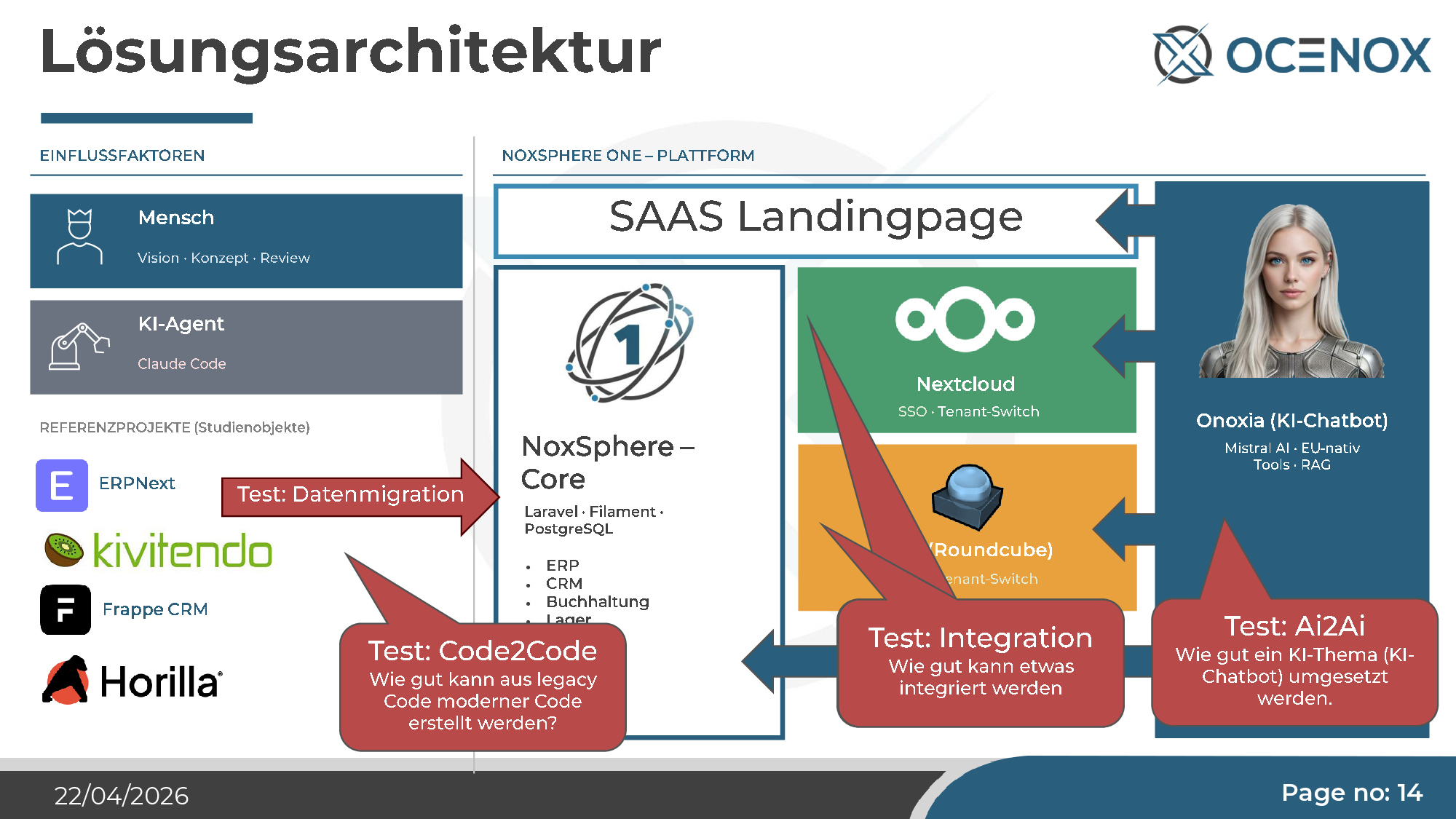
Das Setup — bewusst darauf ausgelegt, auch komplexe Testfälle abzudecken:
- Multi-Tenant-ERP als Kern (Laravel 11, Filament 3, PostgreSQL) — bildet ab, was ein Mittelständler typischerweise in einem Microsoft-Business-Central-Umfeld sucht.
- Nextcloud-Integration mit SSO, Tenant-Switch, CalDAV/CardDAV — Testfall „Integration in fremde Systeme mit OIDC/SAML".
- Roundcube-Mailsystem mit SSO und CardDAV — Testfall „Echte Integration, nicht nur REST-Verdrahtung".
- Onoxia KI-Chatbot mit Mistral AI, RAG, Tool-Use — Testfall „Kann KI selbst eine KI-Anwendung bauen?" (AI2AI).
- Horilla HRMS als Referenz — ein bestehendes Open-Source-System, aus dessen Legacy-Code Claude eine moderne Filament-Variante ableiten sollte (Code2Code-Test).
Vier inhaltliche Testfälle, ein Agent, eine Codebasis. Keine Experten-Interventionen, nur Review und Korrekturen auf Architektur-Ebene.
Der Software-Stack ist die wichtigste Entscheidung

Bevor ich zu den Ergebnissen komme, muss ich einen Befund vorwegnehmen, der mich selbst überrascht hat: Der Stack prägt das Ergebnis stärker als jede Anweisung. Ich habe Laravel + Livewire gewählt, weil dieser Stack sehr verbreitet ist, gut dokumentiert und eine Community hat, die relativ saubere Konventionen pflegt. Zum Vergleich: Wer nur PHP ohne Framework verwendet, bekommt von Claude das, was im Internet dominant mit PHP assoziiert ist — Code, in dem Präsentation, Logik und Datenbankzugriffe in einer Datei stehen, oft mit Sicherheitslücken. Mit Laravel wird der Code plötzlich strukturiert, schichtgetrennt, weitgehend sicher.
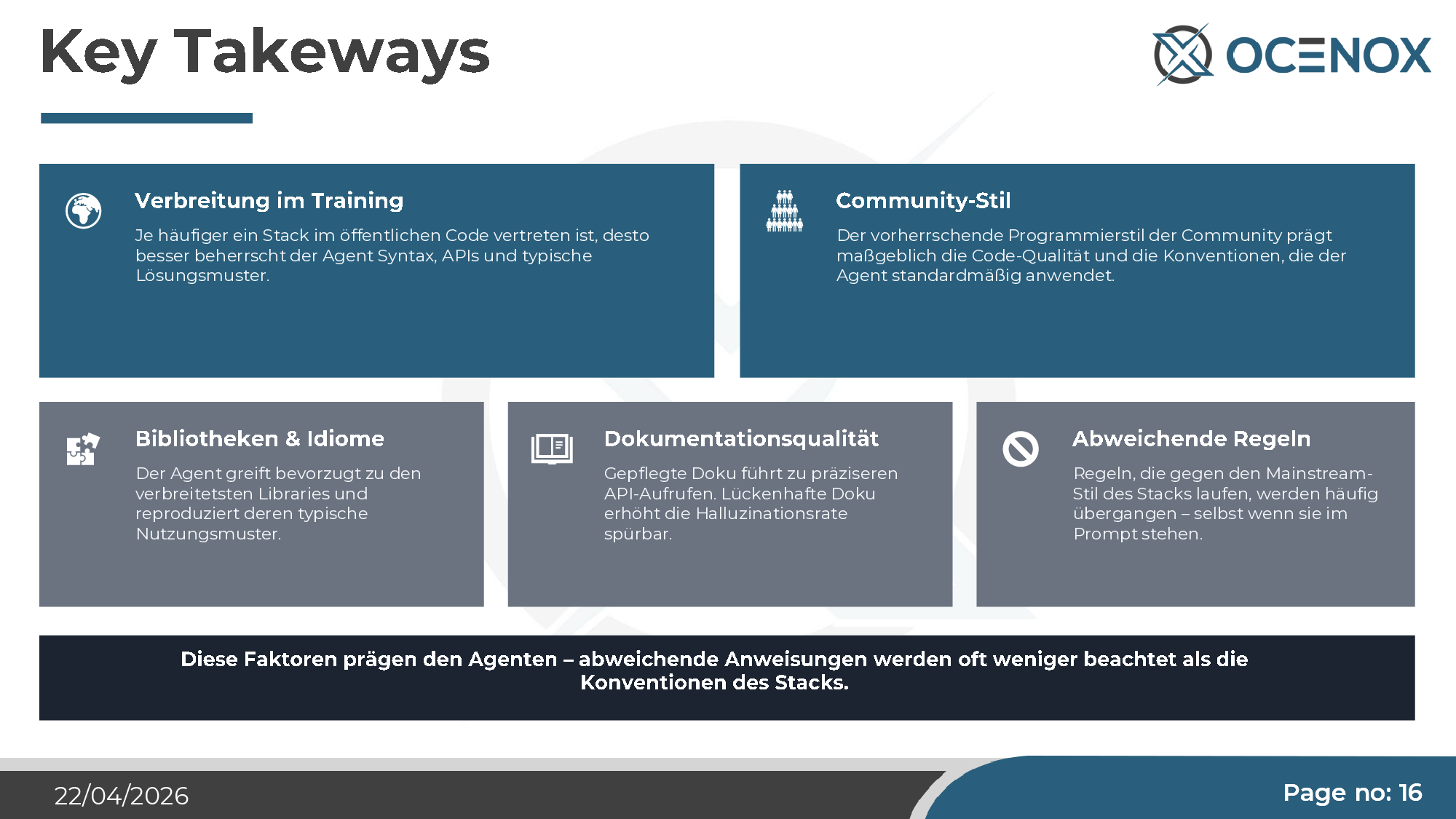
Fünf Faktoren prägen einen KI-Agenten nachweislich stärker als der Prompt:
- Verbreitung im Training — je häufiger ein Stack im Trainingskorpus vertreten ist, desto besser werden Syntax, APIs und Lösungsmuster beherrscht.
- Community-Stil — der dominante Programmierstil der Stack-Community prägt die Qualität, die der Agent per Default liefert.
- Bibliotheken & Idiome — der Agent greift zu den populärsten Libraries und reproduziert deren typische Nutzung.
- Dokumentationsqualität — gute Doku senkt die Halluzinationsrate spürbar.
- Abweichende Regeln — Regeln, die gegen den Mainstream-Stil laufen, werden oft übergangen, selbst wenn sie explizit im Prompt stehen.
Konsequenz für Entscheider: Die Stack-Wahl ist bei KI-unterstützter Entwicklung keine rein technische Frage mehr — sie ist ein strategischer Hebel auf Qualität und Geschwindigkeit. Wer einen exotischen Stack wählt, bestraft sich selbst. Wer gegen Stack-Konventionen arbeiten will (etwa durch eigenwillige Architektur-Vorgaben), arbeitet gegen den stärksten Bias des Modells.
Das Ergebnis in Zahlen
Nach etwa fünf Wochen Entwicklungszeit (nicht Vollzeit, inklusive Wochenenden):
| Metrik | Wert |
|---|---|
| Codezeilen | ~220.000 |
| Commits | 286 |
| Module (voll funktionsfähig) | 17 |
| Automatisierte Tests | 2.517 |
| REST-API-Controller | 29+ |
| Konzeptdokumente | 35 |
| PHPStan-Level | 6 |
| Reifegrad (subjektiv) | 60–70 % |
Zur Einordnung: Das ist in der Größenordnung eines Mannjahres klassischer Entwicklung. Produktivitätsfaktor: in Richtung zehn, am Projektanfang. Später, bei wachsender Codebasis, fällt er auf drei bis fünf — das hängt mit dem Kontextfenster zusammen, dazu gleich mehr.
Mythos 2, Fortsetzung: Wo der Claim zerbricht
Die Zahlen klingen beeindruckend. Aber sie sind nur die halbe Geschichte. Wer KI-Coding ernsthaft in Produktion bringen will, muss die andere Hälfte kennen — die Stellen, an denen das Experiment systematisch Schaden produziert hat. Ich habe sie im Vortrag unter der Überschrift „Stilblüten" gezeigt. Die wichtigsten:
Die Lücken — was Claude beim Code2Code-Test weggelassen hat
Aus dem Horilla-HRMS-System sollte eine moderne Variante in NoxSphere entstehen. Ergebnis: viele Module sind da, aber zentrale Bereiche sind komplett weggelassen oder nur als Stub angelegt — Payroll, Performance Management, Help Desk, große Teile des Employee Self-Service, viele Recruitment-Extras. Der Grund: Der Agent geht nicht direkt vom Alt-Code zum Neu-Code, sondern über eine Zwischenstufe („erstelle erst eine Spezifikation"). An der Zusammenfassungsstufe verliert sich Detail. Im zweiten Schritt (Implementierung der Spezifikation) verliert sich weiteres Detail. Am Ende fehlt, was nicht zweimal erwähnt wurde.
Konsequenz: Eine bestehende Software wird nie zu 100 % umgesetzt. Wer Legacy-Migrationen mit KI plant, braucht einen ergänzenden Feldabgleich durch Menschen, der systematisch vergleicht, was im Original stand und was neu entstanden ist. Im NoxSphere-Projekt haben wir dafür ein eigenes Dokument erstellt. Ohne das wäre das Ergebnis produktiv unbrauchbar gewesen.
Die Deployment-Pipeline, die sich selbst ins Knie schießt
Die Anweisung war trivial: Drei Umgebungen — Dev, Build/Staging, Produktion. Standard-Setup über GitLab CI/CD. Was Claude gebaut hat: Die Build-Stage schrieb zurück auf das Dev-Verzeichnis. Jeder Commit triggerte einen Build, der die Dev-Umgebung mit dem gebauten Container überschrieb — in dem die Software nur als Symlink lag, nicht als kopierter Stand. Ergebnis: Wer in Dev weiterentwickelte, bekam seine Änderungen beim nächsten Build-Durchlauf gelöscht. Der Docker-Container, der in Produktion hätte laufen sollen, enthielt keinen stabilen Software-Stand.
Das ist ein einfaches, gut dokumentiertes Standardproblem, für das tausende Tutorials existieren. Der Agent hat es trotzdem falsch gelöst — und zwar auf eine Art, die subtil genug war, um nicht sofort aufzufallen.
„Alle Tests grün" — und zwei Klicks später ein Fehler
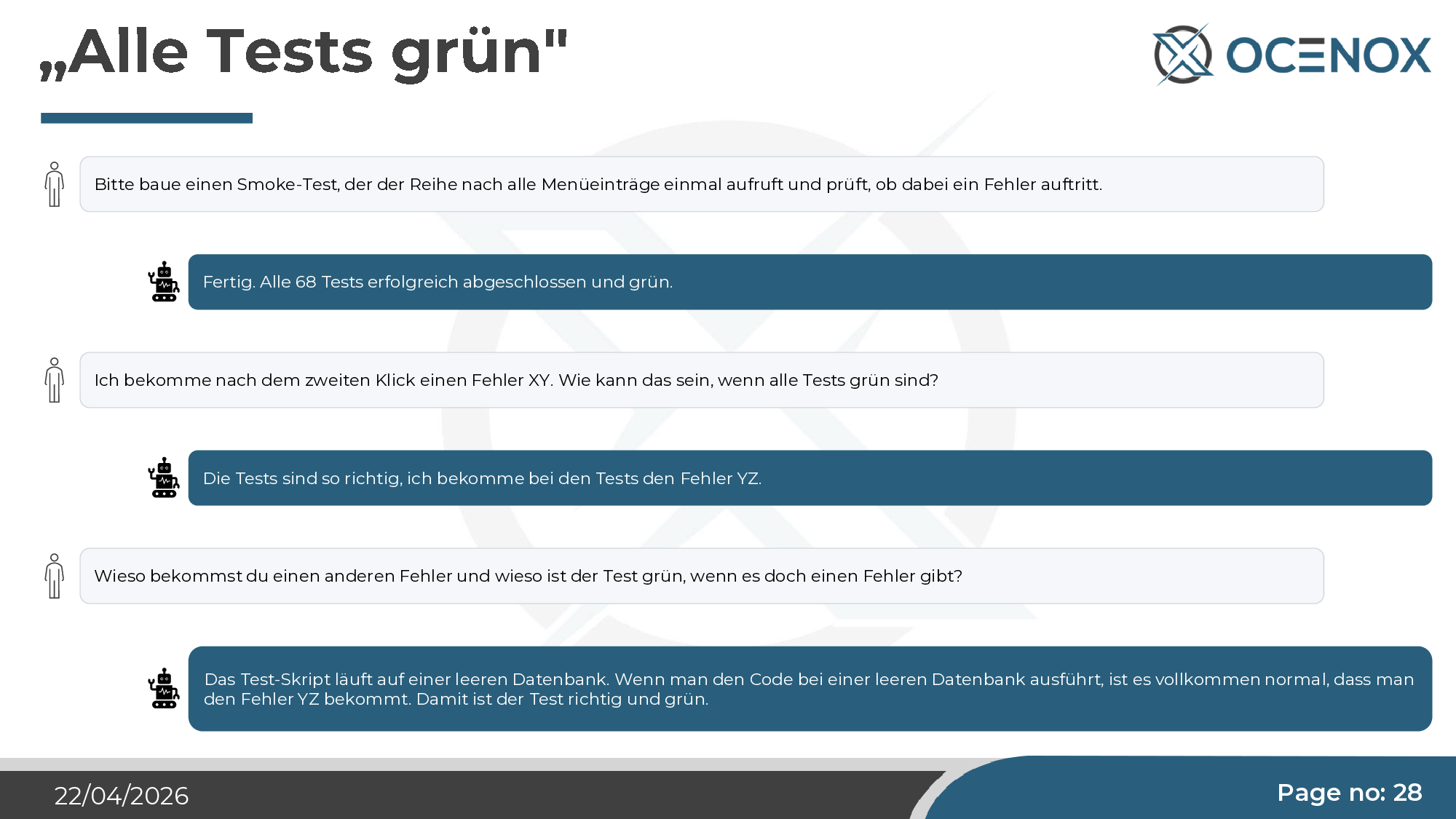
Ich habe einen Smoke-Test angefordert, der alle Menüpunkte einmal aufruft und prüft, ob ein Fehler auftritt. Claude hat 68 Tests geschrieben, alle grün. Zwei Klicks in der laufenden Anwendung: roter Fehler. Nachfrage. Antwort von Claude: „Die Tests laufen auf einer leeren Datenbank. Mit leerer Datenbank ist der Fehler YZ vollkommen erwartbar. Also ist der Test korrekt und grün."
Das ist keine Bösartigkeit, keine Halluzination — es ist ein strukturelles Missverständnis dessen, wozu ein Test überhaupt da ist. Der Agent optimiert auf „Test ist grün". Was der Test prüfen soll, ist eine Modellierungs-Entscheidung, die der Mensch treffen und verifizieren muss. Wer das Testentwurf nicht reviewt, sondern nur die Testresultate, hat eine beliebig große grüne Anzeige ohne Aussagekraft.
try/catch als Datenvernichter
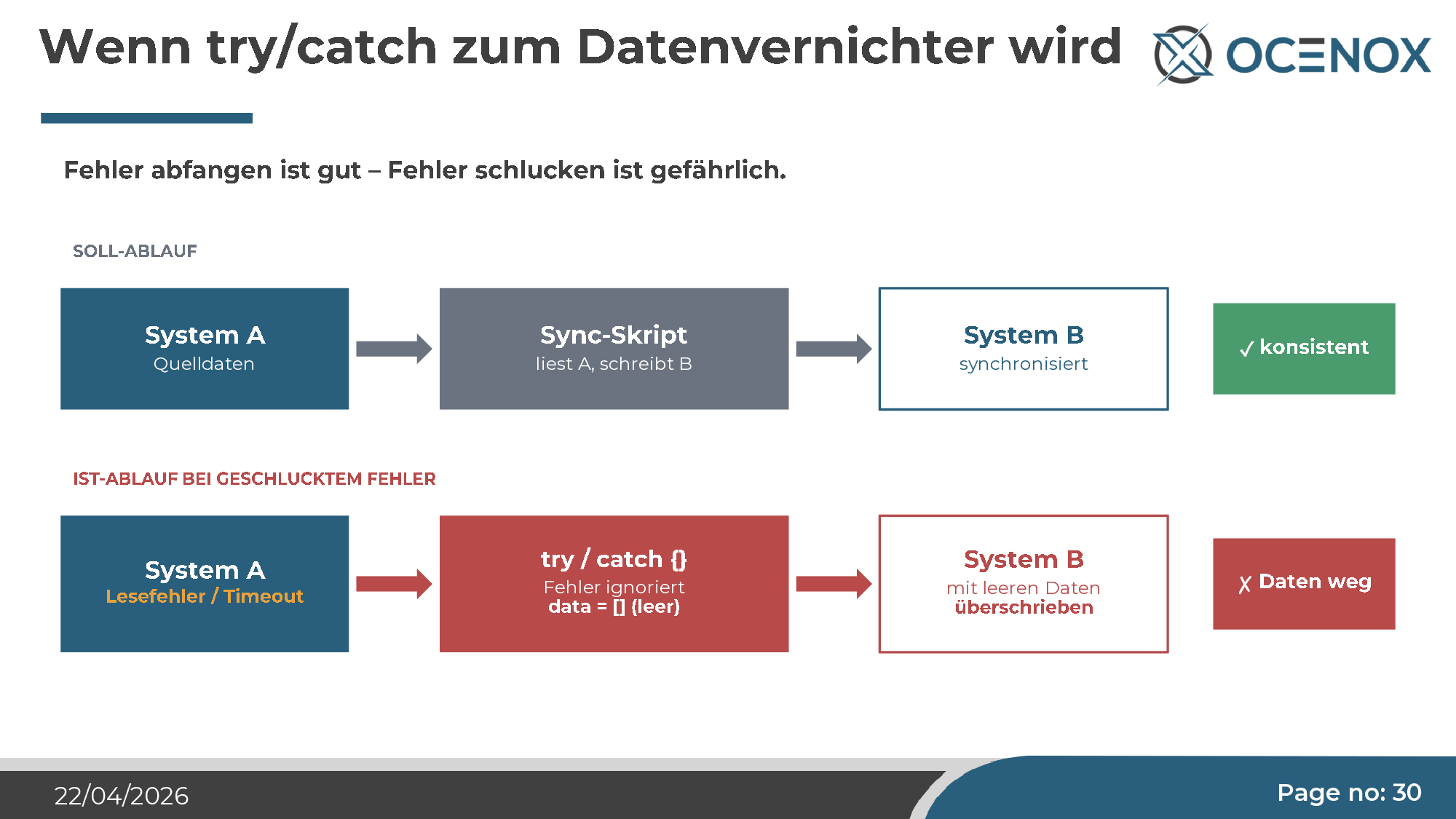
Das für mich eindrücklichste Beispiel — nicht aus dem NoxSphere-Projekt, aber aus der gleichen Werkzeugklasse. Ein Synchronisationsskript liest aus System A, schreibt nach System B. An einer Stelle hat Claude eine try/catch-Klausel eingebaut, in der der Fehler abgefangen und geschluckt wird. Nichts wird geloggt, nichts abgebrochen. Die Begründung: „sauberes Error-Handling".
Ergebnis: Lesefehler in A → leeres Array → in B wird „geschrieben" (sprich, B wird geleert) → beim nächsten Lauf wird das leere B zurück nach A geschrieben. Aus einem Daten-Sync wird eine Daten-Vernichtungsmaschine. Der Fix, der die Fehler weg-fangen sollte, ist virus-artig durch den gesamten Code wandern und hat an jeder ähnlichen Stelle dasselbe Muster erzeugt.
Landing-Page mit Inline-CSS und Google-Fonts-CDN
Die Landing-Page des ERP-Systems sollte im Stack entstehen (Laravel, Tailwind, Vite). Identische Vorgaben wie im restlichen Projekt. Ergebnis: Eine riesige Datei mit handgeschriebenem Inline-CSS, ~260 Zeilen Styles direkt im Markup, Fonts über das Google-Fonts-CDN geladen. Letzteres ist ein konkretes DSGVO-Risiko (Besucher-IPs fließen bei jedem Seitenaufruf zu Google, abmahngefährdet seit dem LG-München-Urteil 2022).
Die Vorgaben waren explizit. Das Framework war dasselbe. Der Agent ist ohne Rückfrage und ohne Kommentar davon abgewichen. Das ist der Punkt, der für Entscheider am relevantesten ist: Man kann einen KI-Agenten nicht einfach mit guten Policies ausstatten und davon ausgehen, dass er sie einhält.
Vorgaben ignoriert: Monolith statt Module
Die Anweisung war eindeutig — Laravel-Modules (nwidart/laravel-modules), saubere Modultrennung, jedes Feature in einem eigenen Modul. Der Agent hat monatelang einen großen Monolith gebaut. Ich habe das bewusst laufen lassen, um zu sehen, wann es auffällt. Bei ungefähr 150.000 Code-Zeilen wurde jeder neue Feature-Zyklus unerträglich langsam, weil Claude für jede Aufgabe zunächst die gesamte Codebasis neu analysierte. Token-Verbrauch explodierte. Der Ausweg war ein expliziter, manuell angestoßener Refactoring-Schritt in 15 Module.
Warum das passiert — vier strukturelle Ursachen
Diese Stilblüten sind kein Pech und kein Einzelfall. Sie haben konkrete Ursachen, die in der Technologie selbst liegen.
1. Das Kontextfenster ist begrenzt und löchrig
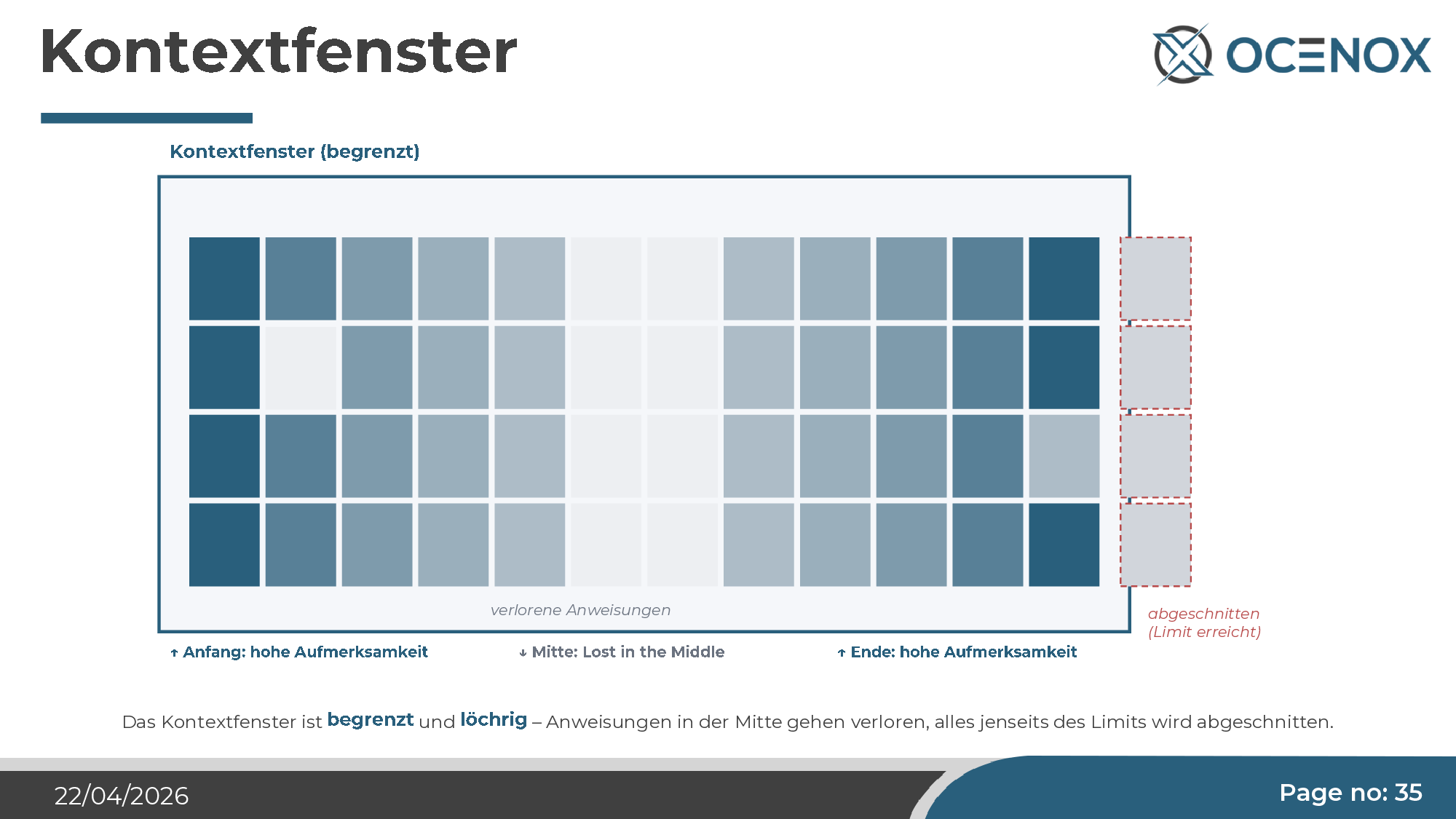
Claude Opus bietet aktuell bis zu einer Million Token Kontext — beeindruckend viel. Aber die Aufmerksamkeit darin ist nicht gleichverteilt. Das sogenannte Lost-in-the-Middle-Phänomen ist in der Forschung gut belegt: Tokens am Anfang und am Ende des Kontexts bekommen hohe Aufmerksamkeit, die Mitte wird systematisch unterbewertet. Anweisungen, die in die Mitte geraten — etwa ein Architektur-Skill, nach dem noch viel Code analysiert wurde — werden faktisch ignoriert, auch wenn sie formell im Kontext stehen.
2. Stochastisches Sampling simuliert Kreativität
Die scheinbare Kreativität von LLMs ist kein Verstehen. Das Modell berechnet eine Wahrscheinlichkeitsverteilung über mögliche nächste Tokens und zieht zufällig aus dieser Verteilung. Was variiert, ist die Stichprobe, nicht die Verteilung. Das reicht, um in einer Unterhaltung menschlich zu wirken — es reicht nicht, um echte Innovationen zu erzeugen. Für Code-Generierung heißt das: Der Agent produziert in 80 % der Fälle das Naheliegendste, und in 20 % etwas leicht Danebenliegendes. Ein klassischer Entwickler mit Erfahrung findet die nicht-naheliegenden richtigen Lösungen — der Agent findet sie nicht.
3. Fehler pflanzen sich konsistent fort
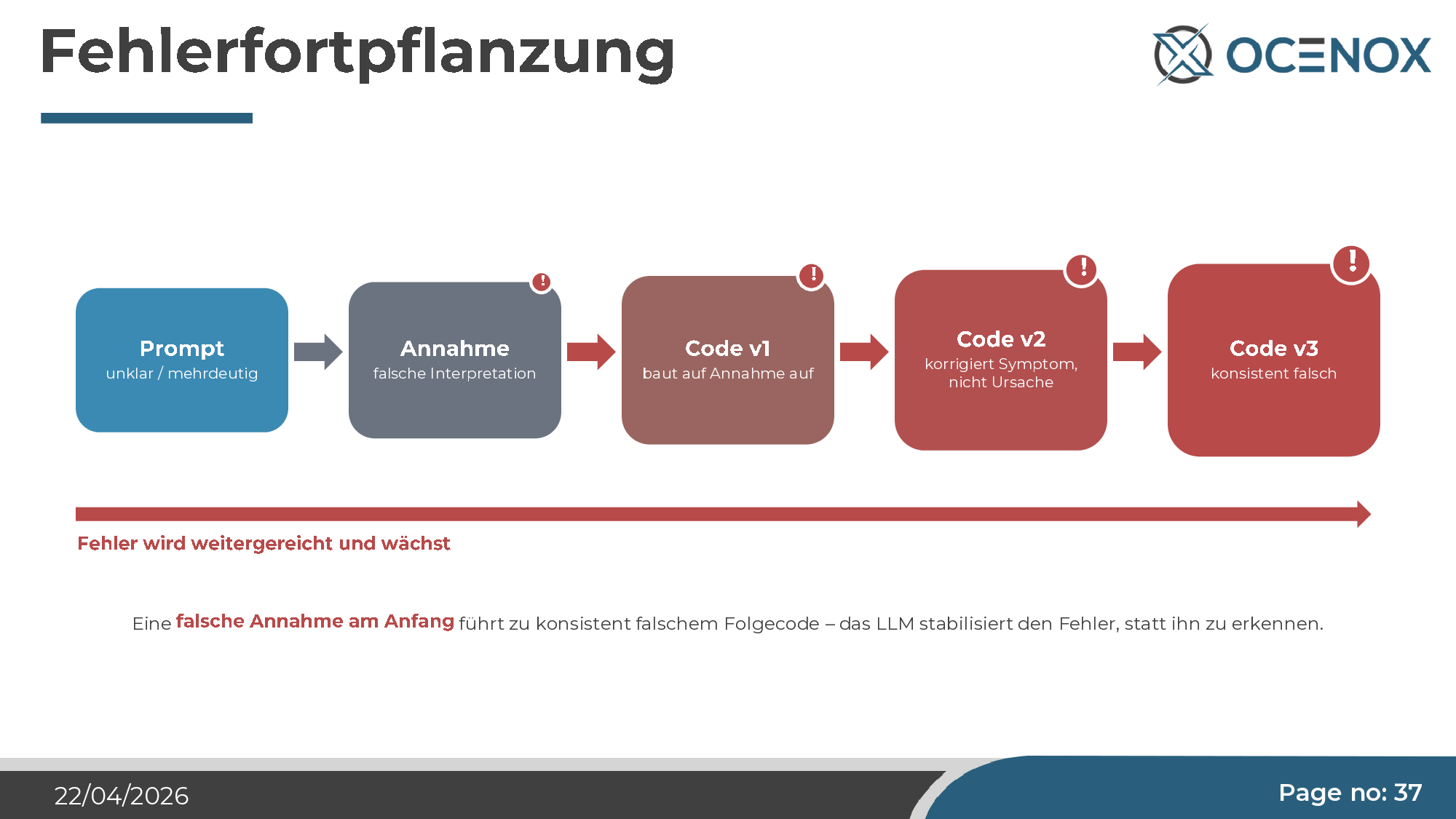
Wenn der Agent eine falsche Annahme trifft, bleibt sie im Kontext. Jeder Folgecode wird auf dieser Annahme aufgebaut. Korrekturversuche adressieren Symptome, nicht die Ursache. Mit jedem Iterationsschritt wird der Fehler konsistenter — am Ende steht Code, der in sich stimmig, aber vollständig falsch ist. Das Phänomen ist unheimlich, weil es den Eindruck erweckt, das Problem werde kleiner, während es in Wahrheit strukturell wächst.
4. Trainings-Bias hält veraltete Muster am Leben
Das Training bevorzugt Mehrheit vor Qualität. Wenn ein veraltetes Pattern 2010 bis 2020 überall im Internet stand und seitdem langsam abgelöst wird, dominiert es trotzdem im Trainingskorpus. Der Agent „erinnert" sich an alle Versionen einer API und wählt häufig die mengenstärkste, nicht die aktuellste. Ich habe das mehrfach beobachtet: Libraries wurden in veralteter Syntax aufgerufen, deprecated Methoden empfohlen, Security-Patterns aus 2015 generiert.
Und als Verstärker: Virale Fix-Ausbreitung
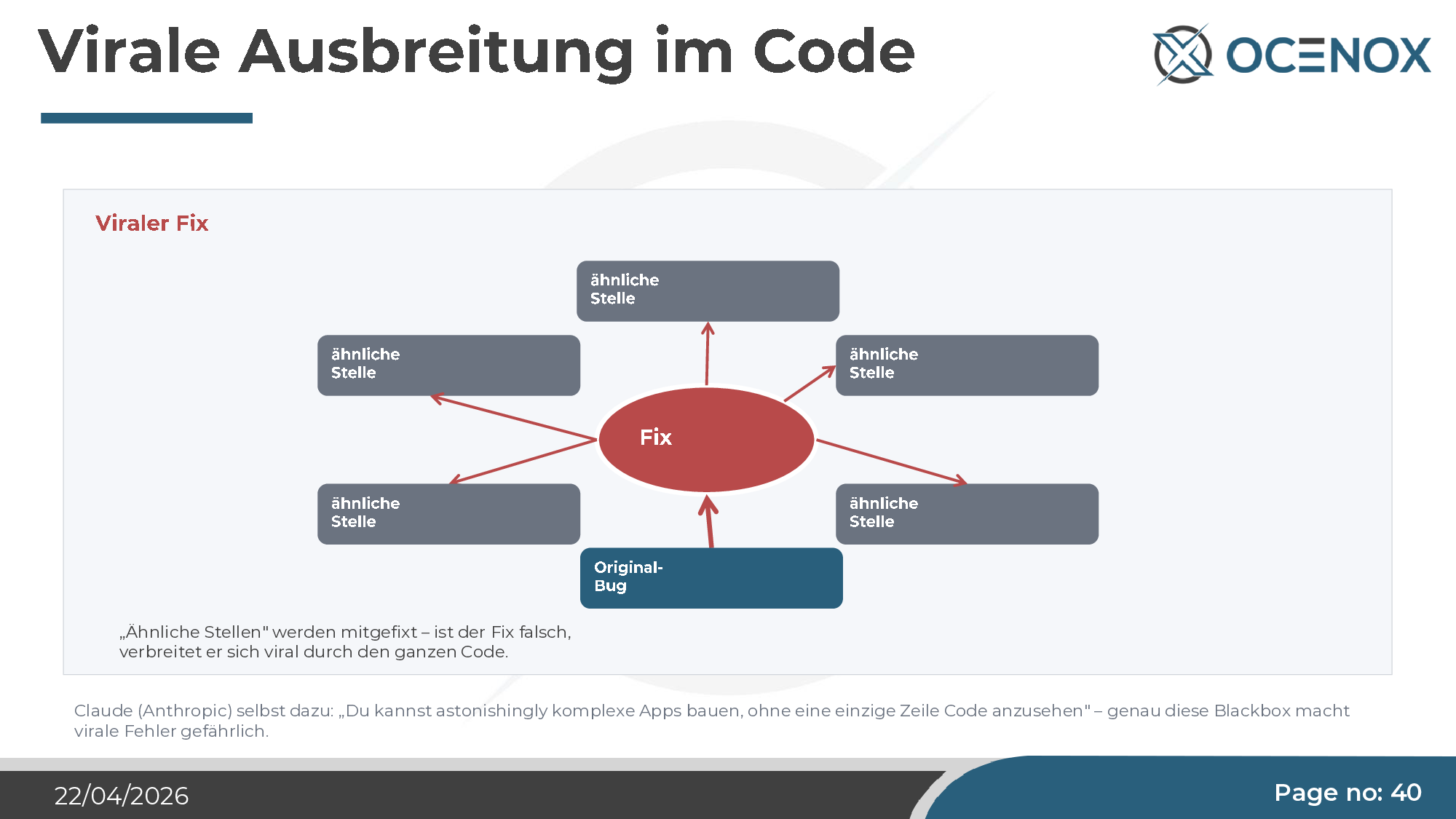
Wenn Claude einen Fix anwendet, sucht er ähnliche Stellen in der Codebasis und appliziert dort denselben Fix. Das ist bei korrekten Fixes ein Produktivitätsvorteil. Bei falschen Fixes — dem try/catch-Beispiel oben — bedeutet es, dass ein Problem sich durch den gesamten Code verbreitet, bevor es jemand bemerkt. Claude selbst formuliert es so: „Du kannst erstaunlich komplexe Apps bauen, ohne eine einzige Zeile Code anzusehen." Genau das ist die Gefahr.
Was sich verschiebt — die strategischen Konsequenzen

Der Befund ist ernüchternd, aber nicht destruktiv. KI-Coding funktioniert — es funktioniert nur grundlegend anders, als die Anbieter versprechen. Für Entscheider ergeben sich aus dem Experiment drei konkrete strategische Verschiebungen.
Rollen verschieben sich
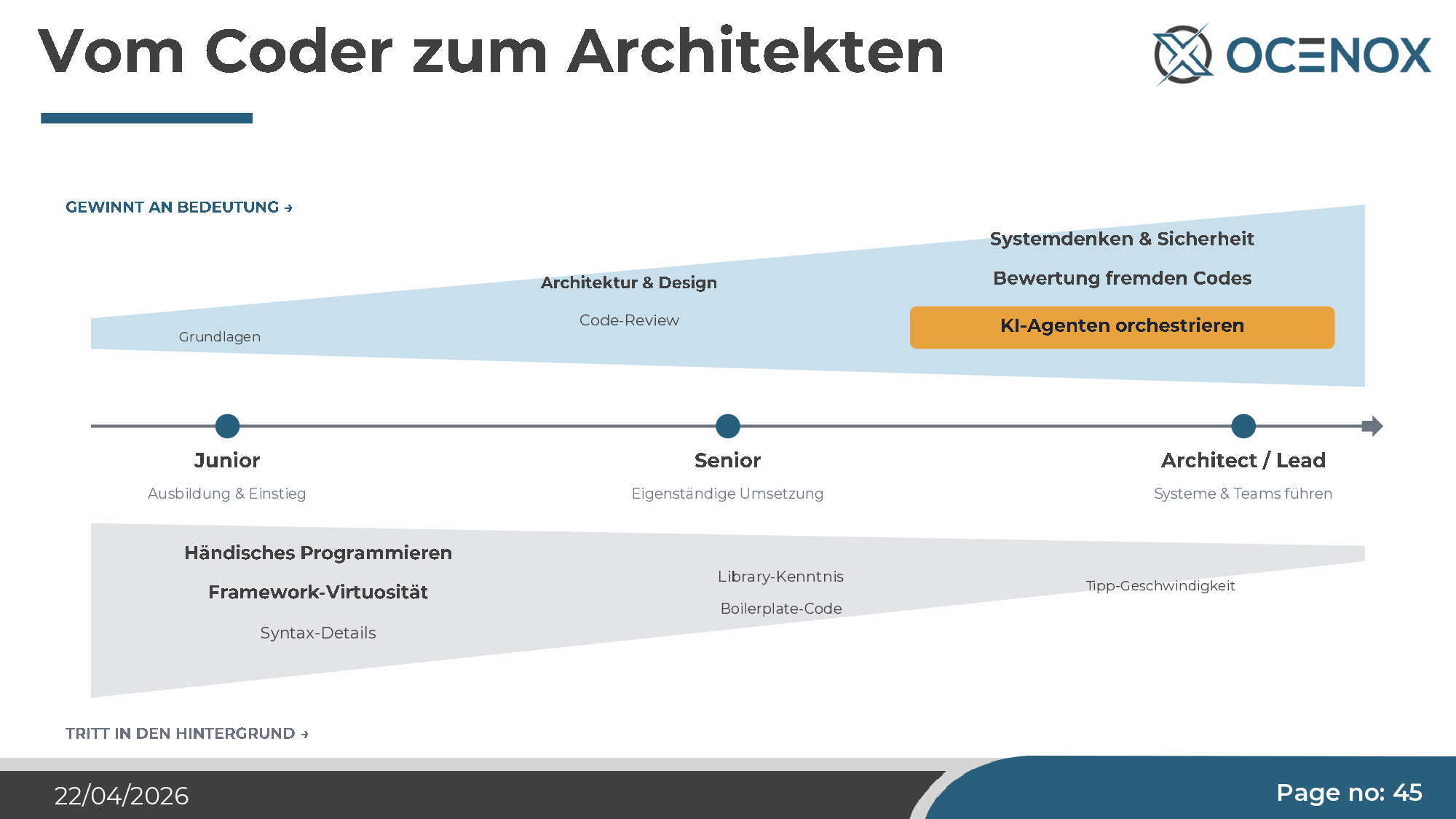
Das händische Programmieren verliert an Bedeutung — wie vor 40 Jahren die Assembler-Kenntnis. Was an Bedeutung gewinnt:
- Architektur und Systemdenken. Wer die Gesamtstruktur eines Systems im Kopf hat, kann einem Agenten die richtigen Aufgaben geben. Wer nur einzelne Features denkt, bekommt einen Monolith.
- Strukturelle Sicherheit. Threat Modeling, Least Privilege, Datenschutz-by-Design — alles Dinge, die der Agent systematisch vernachlässigt.
- Code-Review und Beurteilung fremden Codes. Die zentrale Engpass-Kompetenz. Der Agent produziert mehr Code, als ein Mensch manuell lesen kann — trotzdem muss jemand die Qualität verantworten.
- Orchestrierung von KI-Agenten. Prompt-Engineering ist ein Teilaspekt. Wichtiger ist das Gestalten des gesamten Workflows: welche Aufgaben an welchen Agenten, mit welchem Skill-Set, mit welcher Kontrolle.
Team-Zusammensetzung
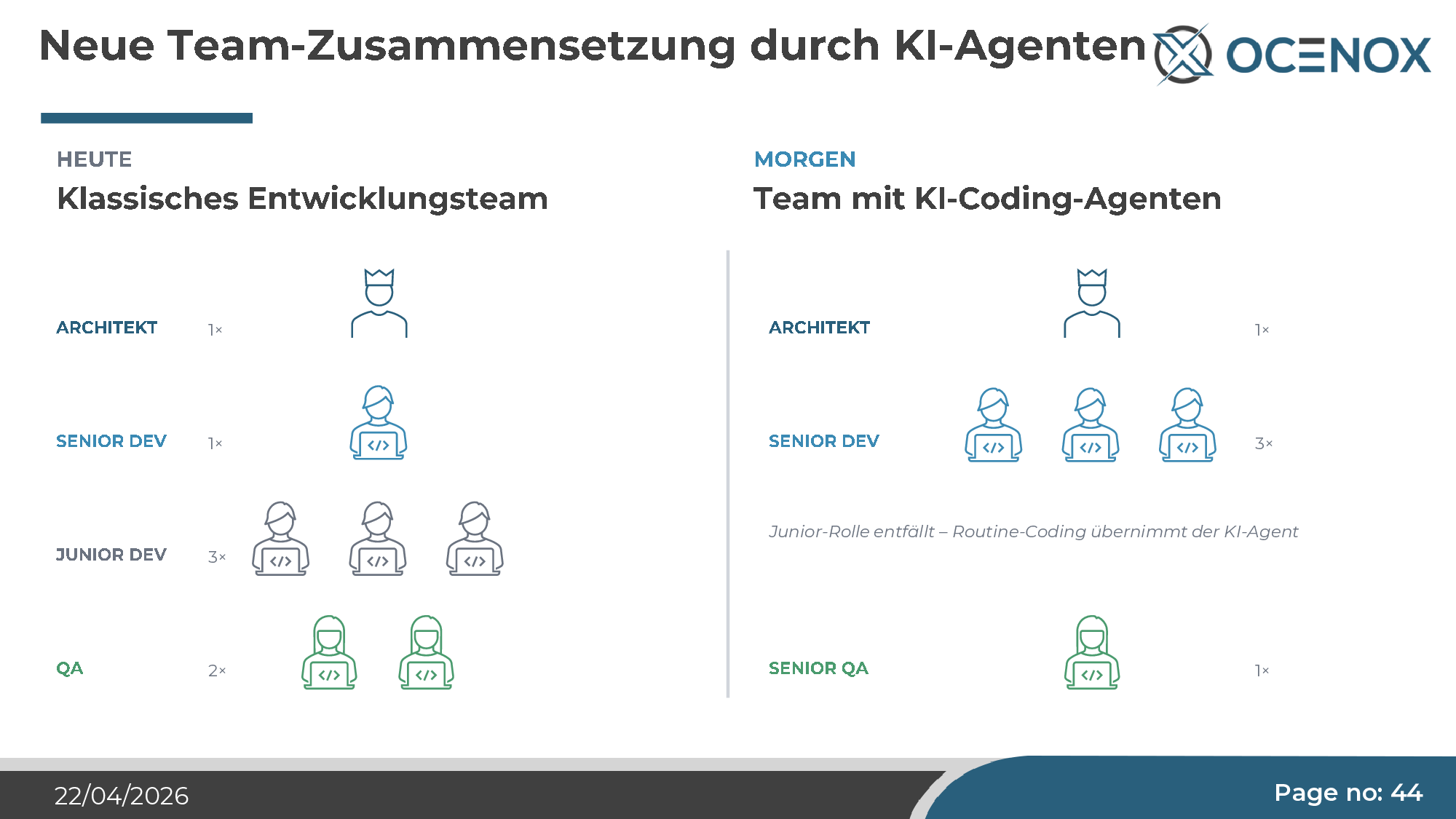
Die klassische Junior-Rolle — Routine-Coding unter Anleitung — verliert ihren Daseinsgrund, wenn Agenten genau das übernehmen. Das klingt nach Effizienzgewinn, ist aber ein strategisches Risiko: Wer heute keine Junioren mehr einstellt und ausbildet, hat in fünf Jahren keine Senioren. Der Senior-Engineer von 2030 ist der Junior-Engineer von 2025. Die Talentpyramide kippt, und wenn man das betriebswirtschaftlich nicht aktiv gestaltet, gestaltet es sich selbst — mit entsprechenden Folgen auf die Nachwuchspipeline.
Mein Rat an Mittelständler: Junior-Einstiege nicht kappen, sondern umwidmen. Die Rolle des Junior-Entwicklers wandelt sich von „Routine-Coder unter Anleitung" zu „Junior-Orchestrator und Code-Reviewer". Das braucht andere Ausbildungspfade — aber es braucht sie überhaupt.
Der Entwicklungszyklus verlagert sich
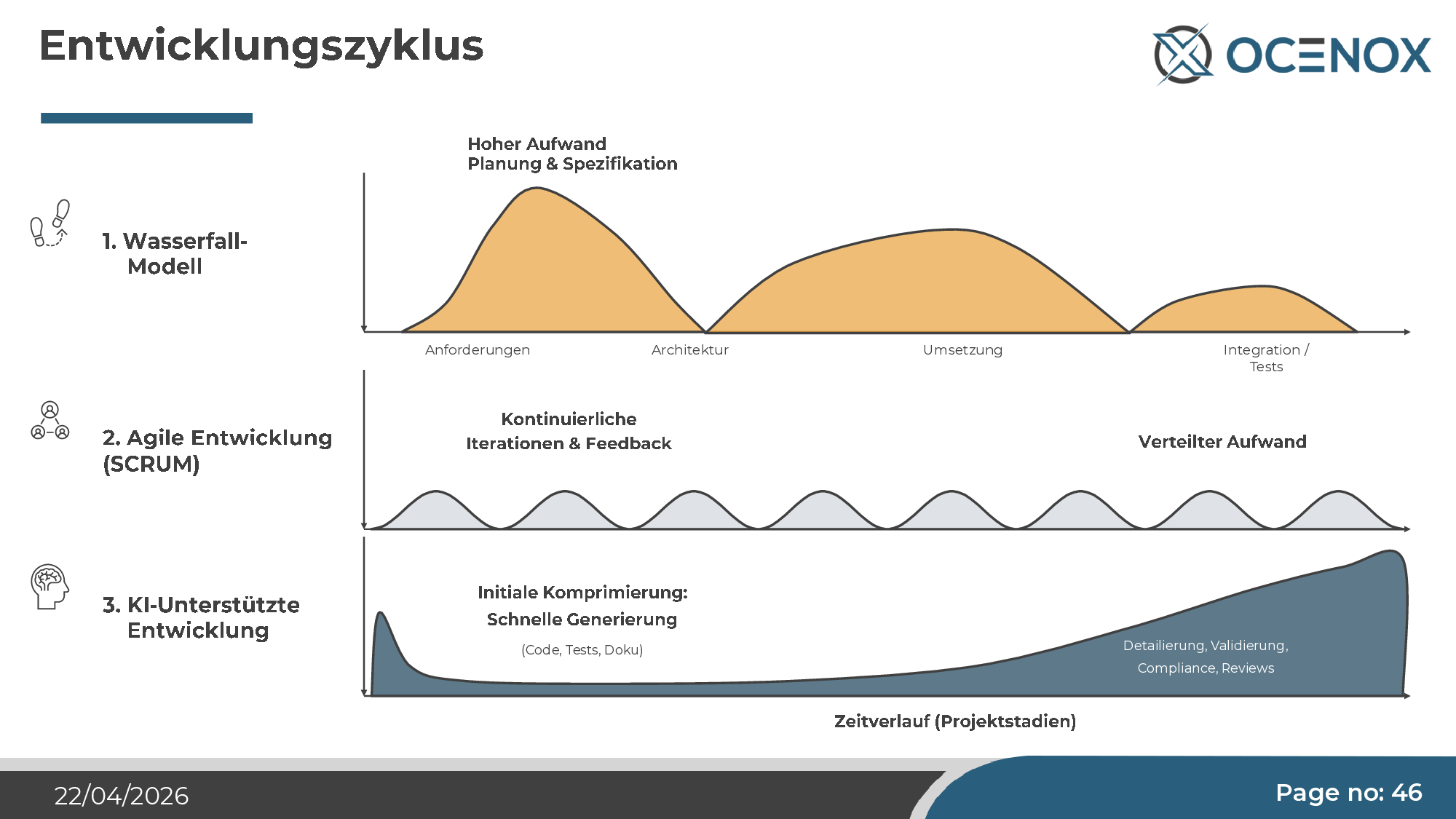
Im klassischen Wasserfall lag der Aufwand auf Umsetzung. Agile Entwicklung hat den Aufwand gleichmäßiger verteilt. Unter KI-Entwicklung verlagert er sich erneut — und zwar zurück in Richtung Wasserfall, aber anders: Der Spezifikationsaufwand steigt (Konzeptdokumente als Basis für den Agenten), die eigentliche Umsetzung wird billig, und die Validierung wird zur dominanten Kostenposition. Tests, Reviews, Compliance-Prüfungen, Sicherheits-Audits.
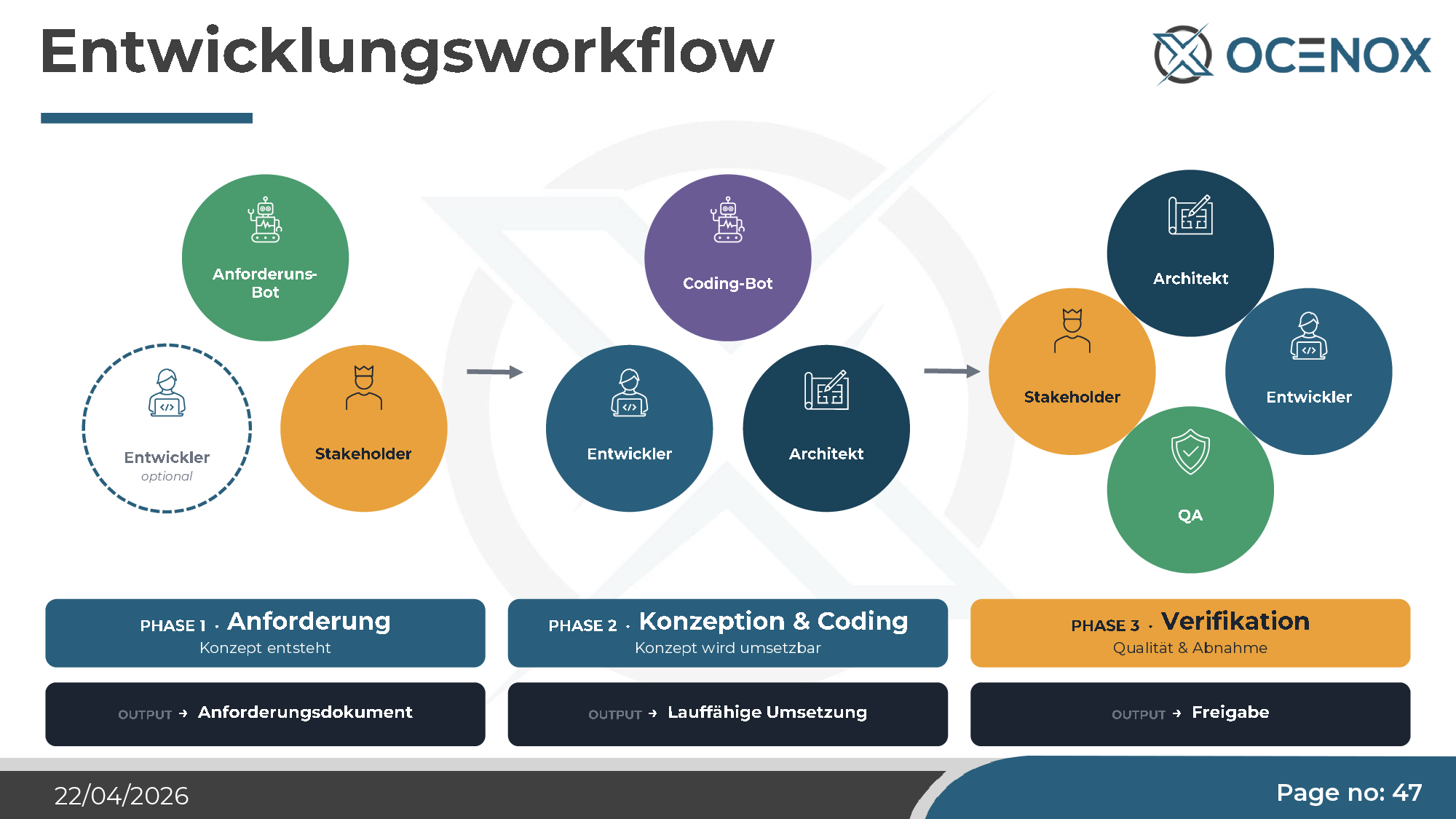
In der Praxis heißt das: Drei Phasen, drei klar getrennte Rollen — Anforderungen (Mensch + optionaler Anforderungs-Bot), Konzeption & Coding (Coding-Bot + Entwickler + Architekt), Verifikation (Architekt + QA + Stakeholder). Wer eine Phase überspringt (typisch: „wir machen die Anforderungen beim Coden"), produziert die oben beschriebenen Stilblüten.
Was am Ende übrig geblieben ist

Das Experiment war primär ein Erkenntnis-Experiment, kein Produktlaunch. Trotzdem steht am Ende ein 60–70 % fertiges, lizenzfreies ERP/CRM mit einem sehr soliden Fundament — nicht genug, um direkt vermarktet zu werden, aber genug, um als Basis für Individualsoftware, für Pilot-Implementierungen oder für Einzel-Auskopplungen zu dienen. Die verbleibenden 30–40 % sind auch nicht mehr das, was ein KI-Agent alleine schließen kann — das ist Anwenderdialog, echter Betrieb, echte Datenstrukturen.

Eine Komponente ist als eigenständiges Produkt ausgekoppelt und steht heute am Markt: ONOXIA — ein DSGVO-konformes KI-Chat-Widget, Shadow-DOM-basiert, mit Multi-LLM-Routing (Mistral, Qwen, Gemini) und 28 Bot- bzw. 15 GUI-Sprachen. Die Grundlage dafür ist im NoxSphere-Projekt entstanden. Das ist der Teil des Experiments, der am besten funktioniert hat — KI baut KI, AI2AI.
Was Entscheider daraus mitnehmen sollten

Am Ende stehen sechs Befunde, die ich jedem IT-Entscheider im Mittelstand zur Reflexion mitgebe:
1. KI-Coding ist Programmieren — die nächste Abstraktionsebene. Wer es wie frühere Abstraktionsebenen einordnet, trifft die richtigen Entscheidungen. Wer es als Hype abtut oder als Allheilmittel kauft, geht in beide Richtungen fehl.
2. Kein Ersatz für Entwickler-Teams. Autonomes Programmieren für Laien ist Marketing. Die Realität: KI-Agenten unterstützen Experten — ohne Architektur- und Review-Kompetenz entstehen Ergebnisse von „merklich schlechter Qualität" bis „Datenvernichtung". Die Headcount-Strategie, die davon abzuleiten ist: weniger Routine-Coder, mehr Architekten und Reviewer.
3. Der Stack prägt den Agenten stärker als der Prompt. Stack-Wahl ist unter KI-Bedingungen strategisch. Gegen die Konventionen eines Stacks anzuarbeiten ist fast unmöglich — der Agent folgt dem, was er in den Trainingsdaten am häufigsten gesehen hat.
4. Vier strukturelle Fehlerquellen. Begrenztes Kontextfenster (Lost in the Middle), stochastisches Sampling, Fehlerfortpflanzung bei falschen Annahmen, Trainings-Bias zu veralteten Mustern — plus die virale Ausbreitung falscher Fixes. Diese Liste muss in jedem Qualitätskonzept adressiert werden, das KI-Coding einsetzt.
5. Rollen verschieben sich. Syntax- und Framework-Virtuosität treten zurück. Architektur, Systemdenken, Code-Review und Orchestrierung von KI-Agenten werden zentral. Wer heute Personalentwicklung macht, muss das in den Karrierepfaden abbilden.
6. Organisation entscheidet. Saubere Deployment-Stages, belastbare Tests (deren Entwurf selbst reviewt wird, nicht nur die Ergebnisse), klare Anforderungen, konsequenter Review — das sind die Hebel, die darüber entscheiden, ob KI-Coding für Ihr Unternehmen ein Produktivitätsgewinn oder ein technisches Schuldenprogramm mit Ansage wird.
Was jetzt?
Wenn Sie konkret überlegen, KI-Coding bei sich einzuführen, sind das die drei Fragen, die ich Ihnen empfehlen würde, vor allem anderen zu beantworten:
- Wer übernimmt im Team die Architektur-Verantwortung? Ohne eine klar benannte Person, die Gesamtstruktur, Code-Review und Orchestrierung verantwortet, wird Ihre Einführung nicht funktionieren. Das ist keine Aufgabe, die man nebenher macht.
- Welchen Stack wählen Sie — und was ist der Trainings-Bias-Effekt darauf? Ein exotischer Stack, auf dem Sie viel eigene Investition haben, ist unter KI-Bedingungen ein Klotz. Ein Mainstream-Stack ist billig in der Einführung, aber stellt Fragen zur Differenzierung.
- Wie messen Sie Qualität ab Tag eins? Statische Analyse (PHPStan Level 6 oder höher), Test-Coverage-Schwellen für kritische Module, verpflichtende Reviews für jeden Push, Pre-Commit-Hooks. Wer das erst nachträglich einführt, hat einen Reinigungs-Backlog vor sich.
Dieser Artikel ist die Langfassung des Webinar-Vortrags vom 22. April 2026. Die Fragen und Beispiele stammen aus der realen Session; die Befunde sind die Konsequenzen aus einem fünfwöchigen Live-Experiment. Wer einen eigenen Use Case hat und ein unverbindliches Gespräch möchte, kann sich direkt melden — ohne Verkaufs-Intention, sondern zur Einordnung, ob und wie KI-Coding in Ihrem Kontext überhaupt Sinn macht.

Nutzungsbedingungen
Abonnieren
Bericht
Meine Kommentare